Недавно мне нужно было взять несколько страниц из PDF файла и сохранить их в новом PDF файле. Это простая задача, но делая её каждый раз, у меня уходит время на определение нужных параметров командной строки, что бы процесс пошел. Кроме этого, моим коллегам нужна была аналогичная функциональность. Так как им не очень удобно работать в командной строке, я решил создать небольшой графический интерфейс, чтобы решить эту проблему.
Одно из решений – использовать Gooey. Это действительно хороший вариант. Однако, я хочу попробовать воспользоваться другой библиотекой. Мой выбор пал на appJar. В этой статье мы пройдемся по примерам использования appJar для создания графического интерфейса, который позволяет пользователю:
- Выбирать PDF файл;
- Выделять одну или несколько страниц;
- Сохранять их в новом файле.
Такой подход простой, эффективный и показывает, как можно интегрировать графический интерфейс в то или иное приложение Python, над которым вы работаете.
Выбор графического интерфейса в Python
Один из базовых вопросов, возникающих в сабреддите Pyhton, это что-то в духе: «Какой графический интерфейс лучше всего использовать?». На самом деле, вариантов очень много, но для освоения большей части интерфейсов нужно много времени усилий. Кроме этого, одни из них работают только на определенных платформах, другие временно не работают. Так что не так уж и просто ответить на этот вопрос.
Доступны следующие категории графических интерфейсов для высокого уровня:
- PyQt;
- wxPython;
- Tkinter;
- PyCairo;
- Пользовательские библиотеки (Kivy, Toga, и т.д.);
- Варианты на базе веб-технологий (HTML, Chrome).
В довесок к этой экосистеме, существует несколько типов оболочек и вспомогательных приложений, упрощающих проведение разработки. Например: Gooey — отличный способ использовать argparse для создания пользовательского интерфейса wxPython совершенно бесплатно. Лично у меня было много хороших примеров использования данного подхода, позволяющего конечному пользователю взаимодействовать с моими скриптами Python. Настоятельно рекомендую. Особенно с тех пор, как wxPython стал работать только на Python 3.
Недостаток Gooey в том, что возможность создавать приложение вне «полномочий» Goeey ограничена. Мне хотелось найти что-то, что отвечает следующим требованиям:
- Легко использовать для создания быстрого и грязного скрипта;
- Предоставляет больше возможностей для взаимодействий, чем это делает командная строка;
- Работает и подходит для Windows;
- Простая установка;
- Активно поддерживается;
- Быстро запускается;
- Возможность также работать и на Linux – определенно плюс;
В конечном счете, я пришел к выводу, что appJar соответствует всем моим требованиям.
Что такое appJar?
appJar был разработан преподавателем, которому нужно было упростить процесс разработки пользовательского интерфейса для его студентов. Приложение предоставляет оболочку вокруг Tkinter (стоит по умолчанию в Python), и заметно упрощает шаблон при разработке приложения.
Это приложение находится в активной разработке. Фактически, новое издание появилось незадолго до того, как я написал эту статью. Документация весьма обширная, в нее входит большое количество отличных примеров. У меня ушло всего несколько часов на то, чтобы разобраться, что к чему, в результате я создал отличное, рабочее приложение. Более того, я использую финальную версию приложения на постоянной основе, когда нужно изъять выбранные страницы из PDF файла. Также я могу расширить его, добавив возможность объединения нескольких документов в один.
Перед тем как дальше углубимся в вопрос, я хочу уделить немного времени Tkinter. Я знаю, что у Tkinter немного подорванная репутация, во многом из-за его несовременности. Однако, с обновленными темами ttk он стал выглядеть лучше. Кроме этого, я думаю, что итоговое приложение хорошо работает на Windows.
В контексте Linux все не так гладко, но приложение действительно работает. В конце концов, данная статья должна помочь вам создать быстрые и эффективные решения для выполнения работы. Если вы ищете безукоризненный пользовательский интерфейс, идеально работающий с вашей ОС, вам могут понадобиться более функциональные варианты. Если вы ищете что-то, что работает быстро – стоит задуматься о appJar.
Чтобы понять, как это выглядит, вот пример рабочего приложения под Windows:
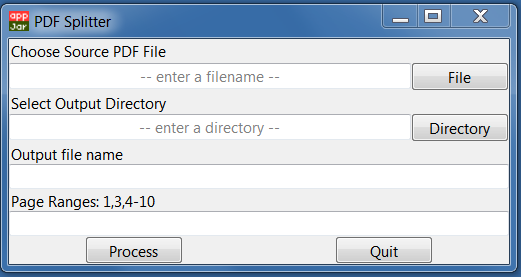
Выглядит вполне ничего себе, на мой взгляд.
Решение Проблемы
Суть данной программы – создать быстрый и простой способ взять подмножество страниц из PDF файла и сохранить его в новый файл. Существует множество программ для Windows, в которых можно проводить данную операцию. Но я обнаружил, что эти «бесплатные» программы включают в себя кучу рекламы, и прочие «полезные» компоненты. Командная строка также работает, но пользовательский интерфейс намного проще, особенно при навигации в куче путей к файлам, или, пытаясь объяснить принцип работы неопытному пользователю.
Чтобы проводить манипуляции с PDF файлом, я использую библиотеку pypdf2. Этот набор инструментов для работы в PDF разработан уже давно и на первый взгляд выглядит немного сложным, но популярность этой библиотеки резко подпрыгнула на github. Еще один приятный аспект — PyPDF2 завернут в Automate The Boring Stuff, так что существует множество дополнительных примеров работы в данной библиотеке.
Начнем с простого скрипта, в который входят сложный ввод, вывод и ранжирование страниц.
|
1 2 3 4 5 6 |
from PyPDF2 import PdfFileWriter, PdfFileReader infile = "Input.pdf" outfile = "Output.pdf" page_range = "1-2,6" |
Далее, мы утверждаем объекты PdfFileWriter и PdfFileReader и создаем файл Output.pdf:
|
1 2 3 |
output = PdfFileWriter() input_pdf = PdfFileReader(open(infile, "rb")) output_file = open(outfile, "wb") |
Самая сложная часть в этом коде, это разделение page_range на последовательный список Python или страниц для извлечения.
Stack Overflow в помощь!
|
1 2 |
page_ranges = (x.split("-") for x in page_range.split(",")) range_list = [i for r in page_ranges for i in range(int(r[0]), int(r[-1]) + 1)] |
Последний шаг, это копирование страницы из входа и её сохранение в выходе:
|
1 2 3 4 |
for p in range_list: # Вычитаем 1 для индекса 0 output.addPage(input_pdf.getPage(p - 1)) output.write(output_file) |
Это все достаточно просто и еще раз доказывает, каким эффективным может быть Python, когда дело доходит до решения реальных проблем. Проблема в том, что данный подход не очень полезный, если речь идет об использовании другими пользователями.
Создание пользовательского интерфейса appJar
Теперь мы можем перейти к интеграции описанного выше куска кода с пользовательским интерфейсом, который будет:
- Давать возможность пользователю выбирать PDF файл при помощи стандартного файлового проводника;
- Выбирать каталог вывода и имя файла;
- Вводить собственный диапазон для извлечения страниц;
- Наличие проверки ошибок, чтобы удостовериться, что пользователь ввел правильные данные;
Для начала, нам нужно установить appJar при помощи:
|
1 |
pip install appjar |
Мы сможем приступить к написанию кода после импорта следующих компонентов:
|
1 2 3 |
from appJar import gui from PyPDF2 import PdfFileWriter, PdfFileReader from pathlib import Path |
Далее, мы можем создать базовое приложение пользовательского интерфейса:
|
1 2 3 4 |
# Создаем окно интерфейса app = gui("PDF Splitter", useTtk=True) app.setTtkTheme("default") app.setSize(500, 200) |
Первые три строчки устанавливают базовую структуру приложения. Я решил установить useTtk=True, потому что с таким параметром, приложение выглядит немного лучше. Недостаток в том, что Ttj все еще в стадии бета, но, на мой взгляд, он отлично подойдет для этого приложения.
Для этой статьи я также решил установить тему по умолчанию. В системе Windows я поставил тему Vista, которая выглядит лучше, на мой взгляд.
Если вы хотите ознакомиться с полным списком доступных в системе тем, используйте app.getTtkThemes() и поэкспериментируйте с параметрами. Далее вы можете ознакомиться с тем, как по разному выглядят темы на Windows и Ubuntu.
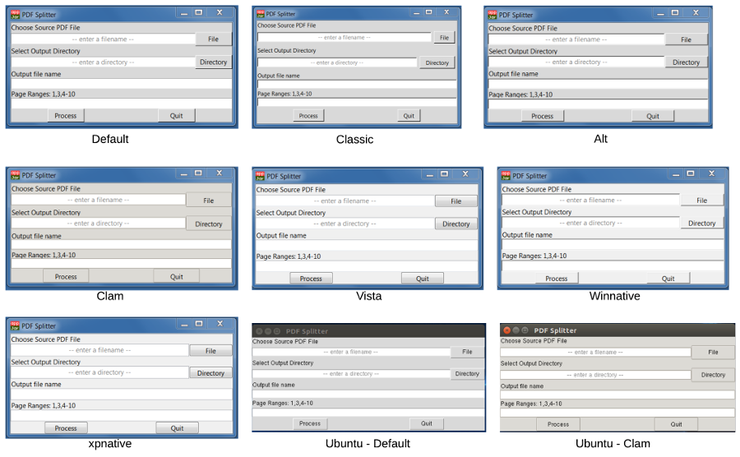
Некоторые различия весьма тонкие, так что можете экспериментировать как угодно и посмотрите, что выйдет.
Следующий шаг: добавим ярлыки и виджеты ввода данных:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# Добавление интерактивных компонентов app.addLabel("Choose Source PDF File") app.addFileEntry("Input_File") app.addLabel("Select Output Directory") app.addDirectoryEntry("Output_Directory") app.addLabel("Output file name") app.addEntry("Output_name") app.addLabel("Page Ranges: 1,3,4-10") app.addEntry("Page_Ranges") |
Для этого приложения я выбираю вызов Label, а затем Entry. appJar также поддерживает комбинированный виджет, под названием LabelEntry, который размещает все в одной строке. По моему опыту, выбор сводится к аскетам, так что попробуйте разные варианты, и определите, какой лучше подходит для вашего приложения.
Самое важное, что нужно помнить, что заключенный в переменных Entry текст будет использован для получения фактического введенного значения.
Следующий шаг – добавить кнопки. В данном коде мы добавим кнопки «Выполнить» и «Выход» (“Process” и “Quit”). Если нажать на любую из кнопок, она вызовет функцию press:
|
1 2 |
# привяжем кнопки к функции под названием press app.addButtons(["Process", "Quit"], press) |
Наконец, перейдем к запуску приложения:
|
1 2 |
# Запуск пользовательского интерфейса app.go() |
Эта базовая структура выполняет большую часть работы интерфейса. Сейчас программа должна читать в любом вводе, проводить проверку и выполнять разделение PDF файла (аналогично примеру выше). Первая функция, которую нам нужно определить – это press. Эту функцию вызывает каждая из кнопок при нажатии.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
def press(button): if button == "Process": src_file = app.getEntry("Input_File") dest_dir = app.getEntry("Output_Directory") page_range = app.getEntry("Page_Ranges") out_file = app.getEntry("Output_name") errors, error_msg = validate_inputs(src_file, dest_dir, page_range, out_file) if errors: app.errorBox("Error", "\n".join(error_msg), parent=None) else: split_pages(src_file, page_range, Path(dest_dir, out_file)) else: app.stop() |
Эта функция берет один параметр – кнопку, которая будет определена как «Выполнить» и, соответственно «Выход». Если пользователь нажмет выход, тогда app.stop() закроет приложение.
Если нажать клавишу выполнить, тогда введенные значения будут извлечены при помощи app.getEntry(). Каждое значение сортируется и утверждается путем вызова функции validate_inputs. Если возникает ошибка, мы можем отобразить ее при помощи всплывающее окно app.errorBox. Если ошибок нет, мы можем разъединить файл при помощи split_pages.
Давайте рассмотрим функцию validate_inputs.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
def validate_inputs(input_file, output_dir, range, file_name): errors = False error_msgs = [] # Проверяет, выбран ли файл PDF if Path(input_file).suffix.upper() != ".PDF": errors = True error_msgs.append("Please select a PDF input file") # Проверят, выбрали ли вы диапазон if len(range) < 1: errors = True error_msgs.append("Please enter a valid page range") # Проверяет доступный ли каталог if not(Path(output_dir)).exists(): errors = True error_msgs.append("Please Select a valid output directory") # Проверка названия файла if len(file_name) < 1: errors = True error_msgs.append("Please enter a file name") return(errors, error_msgs) |
Эта функция выполняет несколько проверок, чтобы убедиться, что данные введены в поля и являются правильными. Я не утверждаю, что это избавит от всех ошибок. Главное, что так вы имеете представление о том, как проводить проверку и собирать ошибки в список.
Теперь, после того как все данные собраны и утверждены, мы можем вызвать функцию split для запуска введенного файла и создания на выходе файла с подмножеством данных.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
def split_pages(input_file, page_range, out_file): output = PdfFileWriter() input_pdf = PdfFileReader(open(input_file, "rb")) output_file = open(out_file, "wb") # https://stackoverflow.com/questions/5704931/parse-string-of-integer-sets-with-intervals-to-list page_ranges = (x.split("-") for x in page_range.split(",")) range_list = [i for r in page_ranges for i in range(int(r[0]), int(r[-1]) + 1)] for p in range_list: # Нужно вычесть 1, так как страницы индексируются как 0 try: output.addPage(input_pdf.getPage(p - 1)) except IndexError: # Предупреждает пользователя и останавливает добавление страниц app.infoBox("Info", "Range exceeded number of pages in input.\nFile will still be saved.") break output.write(output_file) if(app.questionBox("File Save", "Output PDF saved. Do you want to quit?")): app.stop() |
Данная функция открывает несколько дополнительных концептов appJar. Во первых, app.InfoBox используется чтобы дать пользователю понять, когда он входит в диапазон, который содержит больше страниц, чем сам документ. Я решил просто указать обработку до конца файла с последующим уведомлением пользователя.
После сохранения файла, программа использует app.questionBox, чтобы спросить пользователя, хочет он продолжать или нет. Если нет, то мы используем app.stop() и благополучно закрываем программу.
Готовый код
Рассмотрим итоговый вариант (исходный код на github):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 |
from appJar import gui from PyPDF2 import PdfFileWriter, PdfFileReader from pathlib import Path # Определение всех необходимых для обработки файла функций def split_pages(input_file, page_range, out_file): """ Использует PDF файл и копирует диапазон страниц в новый PDF файл Аргументы: input_file: Исходный PDF файл page_range: Строка, содержащая число копируемых страниц: : 1-3,4 out_file: Название назначаемого PDF файла """ output = PdfFileWriter() input_pdf = PdfFileReader(open(input_file, "rb")) output_file = open(out_file, "wb") # https://stackoverflow.com/questions/5704931/parse-string-of-integer-sets-with-intervals-to-list page_ranges = (x.split("-") for x in page_range.split(",")) range_list = [i for r in page_ranges for i in range(int(r[0]), int(r[-1]) + 1)] for p in range_list: # Необходимо вычесть 1, так как страницы индексируются как 0 try: output.addPage(input_pdf.getPage(p - 1)) except IndexError: # Уведомляет пользователя и прекращает добавление страниц app.infoBox("Info", "Range exceeded number of pages in input.\nFile will still be saved.") break output.write(output_file) if(app.questionBox("File Save", "Output PDF saved. Do you want to quit?")): app.stop() def validate_inputs(input_file, output_dir, range, file_name): """ Проверяем, если введенные пользователем значения являются правильными. Аргументы: input_file: Исходный PDF файл output_dir: Директория для хранения готового файла range: File Строка, содержащая число копируемых страниц: : 1-3,4 file_name: Имя вывода готового PDF файла Возвращает: True, если ошибка и False, если нет Список сообщений об ошибке """ errors = False error_msgs = [] # Проверяет, выбран ли PDF файл if Path(input_file).suffix.upper() != ".PDF": errors = True error_msgs.append("Please select a PDF input file") # Проверяет, выбран ли диапазон if len(range) < 1: errors = True error_msgs.append("Please enter a valid page range") # Проверяет действительный каталог if not(Path(output_dir)).exists(): errors = True error_msgs.append("Please Select a valid output directory") # Проверяет название файла if len(file_name) < 1: errors = True error_msgs.append("Please enter a file name") return(errors, error_msgs) def press(button): """ Выполняет нажатие кнопки Аргументы: button: название кнопки. Используем названия Выполнить или Выход """ if button == "Process": src_file = app.getEntry("Input_File") dest_dir = app.getEntry("Output_Directory") page_range = app.getEntry("Page_Ranges") out_file = app.getEntry("Output_name") errors, error_msg = validate_inputs(src_file, dest_dir, page_range, out_file) if errors: app.errorBox("Error", "\n".join(error_msg), parent=None) else: split_pages(src_file, page_range, Path(dest_dir, out_file)) else: app.stop() # Создать окно пользовательского интерфейса app = gui("PDF Splitter", useTtk=True) app.setTtkTheme("default") app.setSize(500, 200) # Добавить интерактивные компоненты app.addLabel("Choose Source PDF File") app.addFileEntry("Input_File") app.addLabel("Select Output Directory") app.addDirectoryEntry("Output_Directory") app.addLabel("Output file name") app.addEntry("Output_name") app.addLabel("Page Ranges: 1,3,4-10") app.addEntry("Page_Ranges") # Связать кнопки с функцией под названием press app.addButtons(["Process", "Quit"], press) # Запуск интерфейса app.go() |
Подведем итоги
Опытные пользователи Python не стесняются использовать командную строку для управления своими приложениями. Однако, существует множество случаев, когда удобнее иметь под рукой простой пользовательский интерфейс. В мире Python много способов создать пользовательский интерфейс. В этой статье мы убедились в том, что создать интерфейс при помощи appJar сравнительно просто. Такое приложение будет работать на нескольких системах, и обеспечивать интуитивные пути взаимодействия пользователя с программой Python. Кроме этого, appJar имеет множество других, не менее полезных функций, которые можно применять в более сложных приложениях.
Надеюсь, данный пример дал вам пищу для новых идей, которые можно реализовать в ваших собственных приложениях. Я думаю, конкретно это приложение удобное и кто-нибудь также найдет ему применение. Оно также может послужить хорошей отправной точкой к другим инструментам работы с PDF файлами.

Являюсь администратором нескольких порталов по обучению языков программирования Python, Golang и Kotlin. В составе небольшой команды единомышленников, мы занимаемся популяризацией языков программирования на русскоязычную аудиторию. Большая часть статей была адаптирована нами на русский язык и распространяется бесплатно.
E-mail: vasile.buldumac@ati.utm.md
Образование
Universitatea Tehnică a Moldovei (utm.md)
- 2014 — 2018 Технический Университет Молдовы, ИТ-Инженер. Тема дипломной работы «Автоматизация покупки и продажи криптовалюты используя технический анализ»
- 2018 — 2020 Технический Университет Молдовы, Магистр, Магистерская диссертация «Идентификация человека в киберпространстве по фотографии лица»