
Если вы только начали знакомство с датасетами или готовитесь к их публикации, визуализация данных очень важна. Pandas является популярной библиотекой для анализа данных в Python, которая предоставляет различные варианты визуализации данных с помощью метода .plot(). Даже если вы только начинаете изучение библиотеки pandas, скоро вы сможете создавать простые графики с ценной информацией о любых данных.
Содержание статьи
- Настройка среды в Python
- Создание простого Pandas графика в Python
- Библиотека Matplotlib в Python
- Изучение данных с помощью графиков в Python
- Распределения и гистограммы в Pandas
- Выбросы в гистограмме
- Проверка корреляции данных
- Анализ категориальных данных
- Группировка данных в Pandas
- Определение соотношений на графике
Темы, рассматриваемые в данном руководстве:
- Различные типы pandas графиков и когда их лучше использовать;
- Как получить обзор вашего набора данных с помощью гистограммы;
- Как обнаружить корреляцию с помощью диаграммы рассеяния;
- Как анализировать разные категории и их соотношения.
Настройка среды в Python
Лучше всего разбирать код из этого руководства в Jupyter Notebook. Таким образом, вы сразу увидите графики и сможете поэкспериментировать с ними.
Вам также понадобится рабочая среда Python, включающая библиотеку pandas. Если у вас её еще нет, то есть несколько вариантов:
- Если вы планируете что-то масштабное, можете скачать дистрибутив Anaconda. Он довольно большой (500 MB), но с ним вы получите почти все инструменты для работы с данными;
- Если вам подойдет минимальный набор инструментов, можете ознакомиться с разделом Installing the Miniconda Python Distribution на странице Setting Up Python for Machine Learning on Windows;
- Если вы хотите использовать pip, тогда установите необходимые библиотеки с помощью команды
pip install pandas matplotlib. Вы также можете установить Jupyter Notebook с помощью командыpip install jupyterlab; - Если вам нужно просто попробовать какой либо код, то воспользуйтесь онлайн пробной версией Jupyter Notebook.
С уже настроенной средой, мы можем скачать тестовый набор данных. В данном руководстве мы проанализируем данные по специальностям выпускников колледжей, полученные в результате исследования American Community Survey 2010–2012, которое находится в общественном доступе. Работа послужила основой для гида по выбору колледжа Economic Guide To Picking A College Major, размещенного на сайте FiveThirtyEight.
Сначала скачиваем данные, для этого передаем URL для скачивания в pandas.read_csv():
|
1 2 3 4 5 6 7 8 9 10 11 |
In [1]: import pandas as pd In [2]: download_url = ( ...: "https://raw.githubusercontent.com/fivethirtyeight/" ...: "data/master/college-majors/recent-grads.csv" ...: ) In [3]: df = pd.read_csv(download_url) In [4]: type(df) Out[4]: pandas.core.frame.DataFrame |
После вызова read_csv() создается DataFrame — главная структура данных, используемая в pandas.
На заметку: Можете воспользоваться данным руководством, даже если вы не знакомы со структурой DataFrame.
При наличии структуры DataFrame вы можете просмотреть данные. Сначала нужно настроить параметр display.max.columns, чтобы убедиться, что pandas не скрывает никакие столбцы. Затем вы можете просмотреть первые несколько строк данных с помощью метод .head():
|
1 2 3 |
In [5]: pd.set_option("display.max.columns", None) In [6]: df.head() |
Только что вы отобразили первые пять строк структуры DataFrame из переменной df, используя метод .head(). Результат выглядит следующим образом:
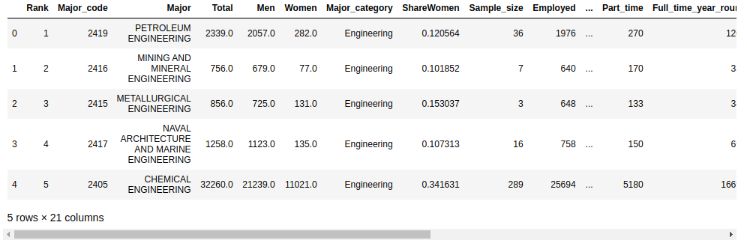
С помощью метода .head() по умолчанию отображается только пять строк, но вы можете указать любое число строк через аргумент. К примеру, для отображения первых десяти строк, мы напишем так df.head(10).
Создание простого Pandas графика в Python
Рассматриваемый набор данных содержит несколько столбцов, связанных с доходами выпускников по каждой специальности:
- «Median» — средний заработок работников, которые заняты полным рабочим днем, круглый год;
- «P25th» — 25-й процентиль заработка;
- «P75th» — 75-й процентиль заработка;
- «Rank» — рейтинг специалиста по среднему заработку.
Начнем с графика, который отображает эти столбцы. Сначала вам потребуется настроить Jupyter Notebook для отображения графиков с помощью магической команды %matplotlib:
|
1 2 |
In [7]: %matplotlib Using matplotlib backend: MacOSX |
Магическая команда %matplotlib настраивает Jupyter Notebook для отображения графиков с помощью Matplotlib. По умолчанию используется стандартный графический бэкенд от Matplotlib, и ваши графики отображаются в отдельном окне.
На заметку: Вы можете изменить бэкенд Matplotlib, передав аргумент в магическую команду
%matplotlib.К примеру, бэкенд
inlineпопулярен для Jupyter Notebooks, потому что он отображает график в самом блокноте сразу под ячейкой, которая создает график:
Есть число доступных бэкендов. Для более подробной информации ознакомьтесь с руководством Rich Outputs в документации IPython.
Теперь вы готовы к созданию первого графика. Это можно сделать с помощью метода .plot():
|
1 2 |
In [8]: df.plot(x="Rank", y=["P25th", "Median", "P75th"]) Out[8]: <AxesSubplot:xlabel='Rank'> |
Метод .plot() возвращает линейный график, который содержит данные из каждой строки структуры DataFrame. Значения по оси х представляют рейтинг каждого учреждения, а значения "P25th", "Median" и "P75th" показываются на оси у графика.
На заметку: Если вы не используете Jupyter Notebook или оболочку IPython, тогда для отображения графика вам потребуется интерфейс
pyplotизmatplotlib.Стандартная оболочка Python отображает график следующим образом:
Обратите внимание, что перед вызовом
plt.show()для отображения графика, нужно импортировать модульpyplotиз Matplotlib.
Фигура, созданная с помощью метода .plot(), отображается в отдельном окне и по умолчанию выглядит следующим образом:
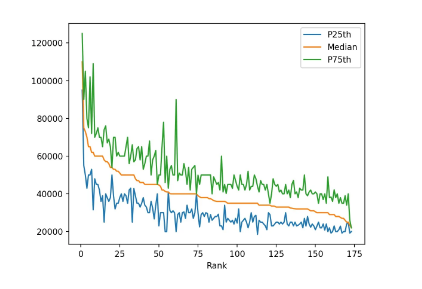
При рассмотрении графика можно сделать следующие выводы:
- Средний заработок уменьшается по мере уменьшения рейтинга. Это ожидаемо, потому что рейтинг определяется средним доходом;
- У некоторых специальностей большой разрыв между 25-м и 75-м процентилями. Люди с этими степенями могут зарабатывать значительно меньше или значительно больше среднего дохода;
- У других специальностей очень небольшой разрыв между 25-м и 75-м процентилями. Люди с такими степенями получают зарплату, очень близкую к средней.
Первый график уже дает понять, что в датасетах можно найти много интересного. У некоторых специальностей есть широкий диапазон заработков, у других он довольно узкий. Для обнаружения этих различий будет использоваться другие типы графиков.
У метода .plot() есть несколько необязательных параметров. В частности, параметр kind принимает одиннадцать различных строковых значений и определяет, какой тип графика создается:
- area для графиков с накоплением;
- bar для вертикальной гистограммы;
- barh для горизонтальной гистограммы;
- box для графиков с боксами;
- hexbin для шестнадцатеричных графиков;
- hist для гистограмм;
- kde для графика оценки плотности ядра;
- density является альтернативным названием для kde;
- line для линейных графиков;
- pie для круговых графиков;
- scatter для графиков рассеяния.
Тип графика по умолчанию является line. Линейные графики наподобие того, что был создан выше, дают хороший обзор данных. Их можно использовать для обнаружения общих трендов. С их помощью не получится сделать глубокий анализ, однако они могут помочь выяснить, на какую область стоит обратить внимание.
Если вы не укажите параметр для метода .plot(), она создаст линейный график с индексом по оси x и всеми числовыми столбцами по оси y. Данный тип графика подходит для наборов данных с несколькими столбцами, но для нашего набора данных по специальностям колледжа с его несколькими числовыми столбцами это выглядит довольно беспорядочно.
На заметку: В качестве альтернативы передаче строк в параметр
kindметода.plot()у объектовDataFrameесть несколько методов, которые можно использовать для создания различных типов графиков, описанных выше:В данном руководстве будет использоваться интерфейс
.plot()и передаваться строки параметруkind. Однако при желании вы можете посмотреть сами, как работают вышеуказанные методы.
Теперь после создания нашего первого pandas графика можно подробнее разобрать, как именно работает метод .plot().
Библиотека Matplotlib в Python
При вызове метода .plot() для объекта DataFrame Matplotlib незаметно создает наш график.
Чтобы убедиться в этом, воспользуемся двумя фрагментами кода. Сначала создадим график с помощью Matplotlib, используя два столбца из структуры DataFrame:
|
1 2 3 4 |
In [9]: import matplotlib.pyplot as plt In [10]: plt.plot(df["Rank"], df["P75th"]) Out[10]: [<matplotlib.lines.Line2D at 0x7f859928fbb0>] |
Сначала импортируется модуль matplotlib.pyplot и переименовывается как plt. Затем вызывается метод plot() и передается столбец "Rank" объекта DataFrame как первый аргумент, а также столбец "P75th" как второй аргумент.
Результатом является линейный график, на котором отображается 75-й процентиль по оси у против рейтинга по оси х.
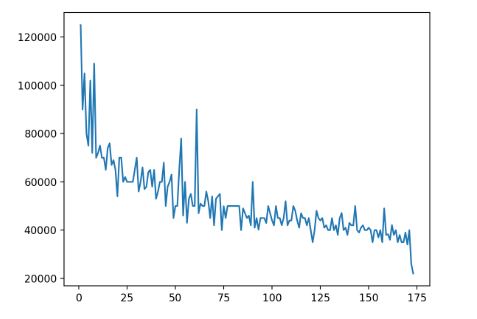
Для создания одного и того же графика из столбцов объекта DataFrame можно воспользоваться как pyplot.plot(), так и df.plot(). Однако, если у вас уже есть экземпляр DataFrame, тогда лучше использовать более чистый синтаксис df.plot(), а не pyplot.plot().
На заметку: Если вы уже знакомы с Matplotlib, вас может заинтересовать параметр
kwargsдля.plot(). Вы можете передать ему словарь, содержащий аргументы, которые затем будут переданы в бэкэнд Matplotlib для построения графиков.
Теперь, когда вы знаете, что метод .plot() объекта DataFrame является оболочкой для pyplot.plot() от библиотеки Matplotlib, давайте рассмотрим различные типы графиков и способы их создания.
Изучение данных с помощью графиков в Python
Следующие графики дадут общий обзор определенного столбца указанного набора данных. Сначала мы рассмотрим распределение собственности с помощью гистограммы. Затем мы познакомимся с некоторыми инструментами для исследования выбросов.
Распределения и гистограммы в Pandas
DataFrame не единственный класс в pandas с методом .plot(). Часто встречаемый в pandas объект Series предоставляет похожую функциональность.
Вы можете представить каждый столбец из DataFrame как объект Series. Далее дан пример использования столбца "Median" из структуры DataFrame, созданной на основе данных специальностей колледжей:
|
1 2 3 4 |
In [12]: median_column = df["Median"] In [13]: type(median_column) Out[13]: pandas.core.series.Series |
При наличии объекта Series вы можете создать на его основе новый график. Гистограмма является хорошим способом визуализировать, как значения распределяются по набору данных. Гистограммы разбивают значения на интервалы (bins) и отображают количество данных, чьи значения находятся в определенном интервале.
Создадим гистограмму для столбца "Median":
|
1 2 |
In [14]: median_column.plot(kind="hist") Out[14]: <AxesSubplot:ylabel='Frequency'> |
Мы вызываем метод .plot() для median_column и передаем строку "hist" параметру kind. Вот и все!
При вызове метода .plot() вы увидите следующую фигуру:
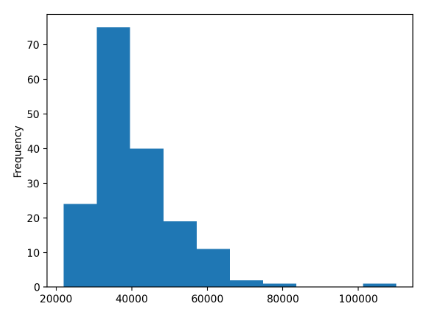
Гистограмма показывает данные в десяти интервалах от $20,000 до $120,000, и ширина каждого интервала составляет $10,000. Форма гистограммы отличается от нормального распределения, у которого симметричная форма колокола с пиком посередине.
На заметку: Для получения более подробной информации о гистограммах ознакомьтесь со статьей Python Histogram Plotting: NumPy, Matplotlib, Pandas & Seaborn.
Однако у гистограммы средних данных есть пики слева ниже $40,000. Хвост тянется далеко вправо и сообщает о том, что есть отрасли, в которых определенные специальности могут рассчитывать на более высокие доходы.
Выбросы в гистограмме
Вы наверняка заметили одинокий маленький прямоугольник с правой части распределения? Кажется, что у некоторых данных есть своя собственная категория. Специалисты в данной области получают отличную зарплату по сравнению не только со средней зарплатой, но и с зарплатой, занявшей второе место. Хотя это не ее основная цель, гистограмма может помочь обнаружить такой выброс. Рассмотрим данный выброс более подробно:
- Какие специальности представляет данный выброс?
- Какова его граница?
В отличие от первого обзора, здесь нужно сравнить только несколько пунктов с данными, но получить о них более подробную информацию. Для этого гистограмма является отличным инструментом. Сначала выбираем пять специальностей с самым высоким средним доходом. Вам предстоит выполнить два пункта:
- Сортировка столбца
"Median"путем использование метода .sort_values(), указывая название столбца, который нужно отсортировать, а также порядок сортировкиascending=False; - Получение пяти первых элементов списка через использования метода
.head().
Создаем новую структуру DataFrame под названием top_5:
|
1 |
In [15]: top_5 = df.sort_values(by="Median", ascending=False).head() |
Теперь у вас есть структура DataFrame меньшего размера, содержащая только пять самых прибыльных специальностей. В качестве следующего шага вы можете создать график, на котором будут показаны только основные специалисты с пятью самыми высокими средними зарплатами:
|
1 2 |
In [16]: top_5.plot(x="Major", y="Median", kind="bar", rot=5, fontsize=4) Out[16]: <AxesSubplot:xlabel='Major'> |
Обратите внимание, что параметры rot и fontsize используются для вращения и изменения размера ярлыков оси x, чтобы они были видны. Вы увидите график с 5 полосами:
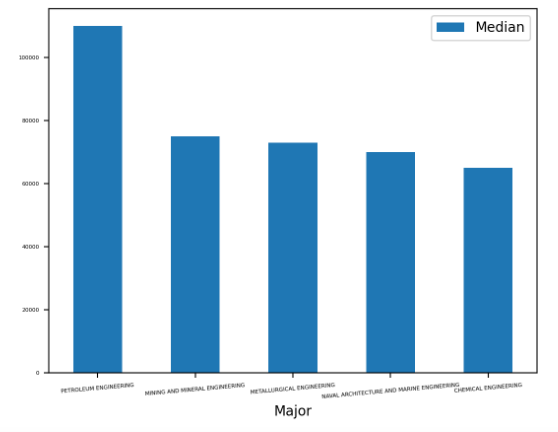
Этот график показывает, что средняя заработная плата специалистов по нефтяной инженерии более чем на $20,000 выше, чем у остальных. Доходы специальностей, занимающих второе-четвертое места, относительно близки друг к другу.
Если у вас есть точка данных с более высокими или низкими значениями, чем остальные, вы, вероятно, захотите изучить ее подробнее. Например, вы можете посмотреть столбцы, содержащие связанные между собой данные.
Рассмотрим все специальности, чья средняя зарплата превышает $60,000. Сначала необходимо отфильтровать основные категории с помощью маски df[df["Median"] > 60000]. Затем вы можете создать еще одну гистограмму, показывающую все три столбца заработков:
|
1 2 3 4 |
In [17]: top_medians = df[df["Median"] > 60000].sort_values("Median") In [18]: top_medians.plot(x="Major", y=["P25th", "Median", "P75th"], kind="bar") Out[18]: <AxesSubplot:xlabel='Major'> |
Вы должны увидеть график с тремя полосками на каждую специальность вроде следующего:
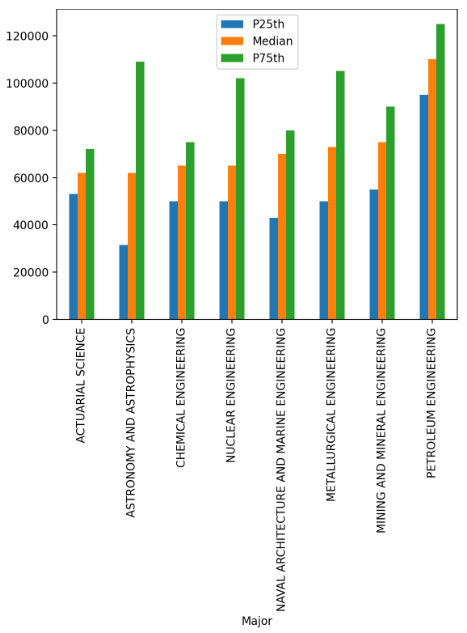
25-й и 75-й процентили подтверждают вышесказанное: выпускники по специальности нефтяной инженерии получали больше всего.
Почему нас интересуют выбросы в этом наборе данных? Студенты при выборе специальности отталкиваются от определенных причин. Однако выбросы также очень интересны с точки зрения анализа. Они могут указывать не только на прибыльные отрасли, но и на поврежденные данные.
Поврежденные данные могут быть вызваны какими либо техническими ошибками или человеческим фактором, такие как отказ датчика, ошибка при ручном вводе данных или участие пятилетнего ребенка в фокус-группе, предназначенной для детей в возрасте от десяти лет и старше.
Даже если данные верны, вам может показаться, что они сильно отличаются от остальных и создают больше шума, чем пользы. Предположим, вы анализируете данные о продажах небольшого издателя. Вы группируете доходы по регионам и сравниваете их с тем же месяцем предыдущего года. Затем совершенно неожиданно издатель выпускает бестселлер.
Такая приятная неожиданность делает ваш отчет бесполезным. С учетом данных о бестселлерах продажи повсюду растут. Выполнение того же анализа без выброса даст более ценную информацию, позволяющую увидеть, что в Нью-Йорке показатели продаж значительно улучшились, но в Майами они ухудшились.
Проверка корреляции данных
Зачастую требуется посмотреть, связаны ли два столбца с наборами данных. Если вы выберете специализацию с более высоким средним заработком, будет ли у вас меньше шансов остаться без работы? На первом этапе создайте диаграмму рассеяния с этими двумя столбцами:
|
1 2 |
In [19]: df.plot(x="Median", y="Unemployment_rate", kind="scatter") Out[19]: <AxesSubplot:xlabel='Median', ylabel='Unemployment_rate'> |
Вы должны увидеть беспорядочно выглядящий график вроде следующего:
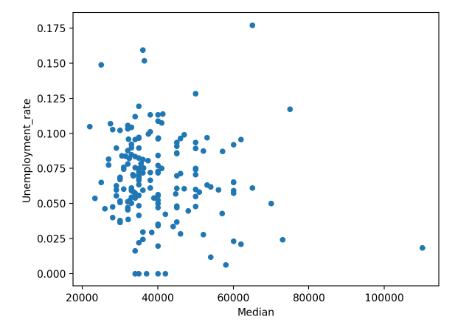
Беглый взгляд на эту фигуру показывает, что нет значительной корреляции между заработком и уровнем безработицы.
Диаграмма рассеяния — отличный инструмент для получения первого впечатления о возможной корреляции, но не является окончательным доказательством наличия связи между данными. Для обзора корреляций между разными столбцами вы можете использовать метод .corr(). Если вы предполагаете, что есть корреляция между двумя значениями, тогда в вашем распоряжении есть несколько инструментов, чтобы проверить свою догадку и измерить, насколько сильна корреляция.
Имейте в виду, что даже если между двумя значениями существует корреляция, это еще не означает, что изменение одного значения приведет к изменению другого. Другими словами, корреляция не предполагает причинной связи.
Анализ категориальных данных
Для обработки больших объемов информации, человеческий разум сознательно и бессознательно сортирует данные по категориям. Этот прием часто бывает полезным, однако он далеко не безупречный.
Иногда мы делим объекты по категориям, которые при внимательном рассмотрении не так уж похожи. В этом разделе вы познакомитесь с некоторыми инструментами для изучения категорий и проверки их целесообразности.
Многие наборы данных уже содержат явную или неявную категоризацию. В текущем примере 173 специализации разделены на 16 категорий.
Группировка данных в Pandas
Категории в основном используются для группирования и агрегирования данных. Вы можете использовать метод .groupby(), чтобы определить, насколько популярна каждая из категорий из набора специализаций:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
In [20]: cat_totals = df.groupby("Major_category")["Total"].sum().sort_values() In [21]: cat_totals Out[21]: Major_category Interdisciplinary 12296.0 Agriculture & Natural Resources 75620.0 Law & Public Policy 179107.0 Physical Sciences 185479.0 Industrial Arts & Consumer Services 229792.0 Computers & Mathematics 299008.0 Arts 357130.0 Communications & Journalism 392601.0 Biology & Life Science 453862.0 Health 463230.0 Psychology & Social Work 481007.0 Social Science 529966.0 Engineering 537583.0 Education 559129.0 Humanities & Liberal Arts 713468.0 Business 1302376.0 Name: Total, dtype: float64 |
С помощью метода .groupby() создается объект DataFrameGroupBy, а с помощью метода .sum() вы создадите Series.
Давайте нарисуем график с горизонтальными полосами, которые будут представлять все категории из cat_totals:
|
1 2 |
In [22]: cat_totals.plot(kind="barh", fontsize=4) Out[22]: <AxesSubplot:ylabel='Major_category'> |
Вы должны увидеть график с горизонтальными полосами для каждой категории:
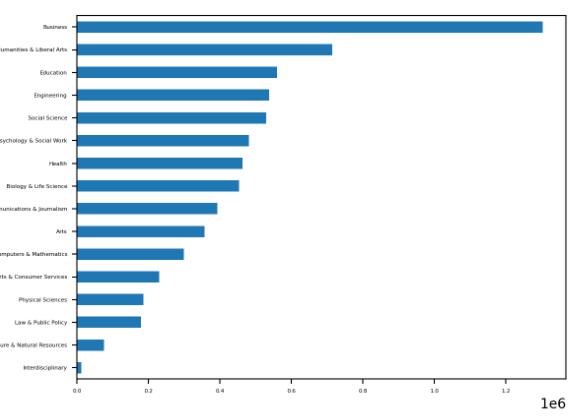
На графике показано, что бизнес является самой популярной специальностью. На втором месте гуманитарные науки и искусство, а оставшиеся категории примерно одинаковы по популярности.
На заметку: Столбец, содержащий категориальные данные, не только дает ценную информацию для анализа и визуализации, но также дает возможность улучшить производительность кода.
Определение соотношений на графике
Вертикальные и горизонтальные гистограммы часто являются хорошим выбором, если вы хотите увидеть разницу между категориями. Если вас интересуют соотношение данных, то круговые диаграммы — отличный инструмент. Поскольку cat_totals содержит только несколько категорий, создание круговой диаграммы с помощью cat_totals.plot(kind="pie") приведет к созданию нескольких крошечных фрагментов с перекрывающимися текстовыми ярлыками.
Для решения этой проблемы можно объединить более мелкие категории в одну группу. Объединим все категории с общим количеством данных меньше 100 000 в категорию под названием «Other» («Другое»), затем создадим круговую диаграмму:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
In [23]: small_cat_totals = cat_totals[cat_totals < 100_000] In [24]: big_cat_totals = cat_totals[cat_totals > 100_000] In [25]: # Adding a new item "Other" with the sum of the small categories In [26]: small_sums = pd.Series([small_cat_totals.sum()], index=["Other"]) In [27]: big_cat_totals = big_cat_totals.append(small_sums) In [28]: big_cat_totals.plot(kind="pie", label="") Out[28]: <AxesSubplot:> |
Обратите внимание, что мы добавили аргумент label="". По умолчанию, pandas добавляет ярлык с названием столбца. Это зачастую имеет смысл, но в данном случае это будет лишним.
Теперь вы должны увидеть круговой график наподобие следующего:
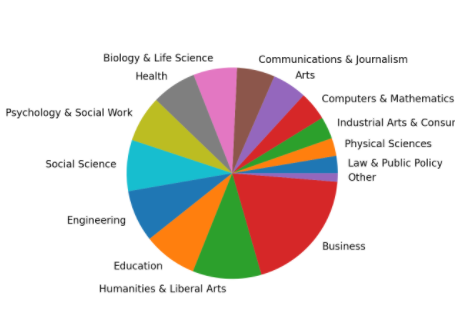
Категория "Other" по-прежнему небольшая. Это хороший признак, значит, мы сделали правильный выбор объединив маленькие категории.
Анализ данных внутри категории
Иногда нужно проверить, имеет ли смысл определенная категоризация. Являются ли элементы категории более похожими друг на друга, чем на остальную часть набора данных?
Опять же, распределение — хороший инструмент для первого обзора нашего набора данных. Как правило, мы ожидаем, что распределение категории будет похоже на нормальное распределение, но с меньшим диапазоном.
Создадим гистограмму, показывающую распределение среднего дохода для инженерных специальностей:
|
1 2 |
In [29]: df[df["Major_category"] == "Engineering"]["Median"].plot(kind="hist") Out[29]: <AxesSubplot:ylabel='Frequency'> |
В результате вы получите гистограмму, которую можно сравнить с гистограммой со всеми главными специальностями, которая балы рассмотрена в начале статьи:
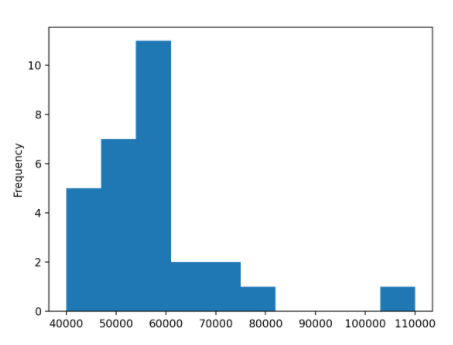
Диапазон основных средних доходов немного меньше, начиная с $40,000. Распределение ближе к нормальному, хотя его пик все же слева. Итак, даже если вы решили выбрать специальность в инженерной категории, было бы разумно более тщательно проанализировать все варианты.
Заключение
В этом руководстве вы узнали, как визуализировать набор данных с помощью Python и библиотеки pandas. Вы увидели, как некоторые базовые графики могут дать представление о данных и помочь выбрать направление для анализа.
В этом руководстве вы узнали, как:
- Сделать анализ распределения набора данных с помощью гистограммы;
- Найти корреляцию с помощью диаграммы разброса;
- Анализировать категории с помощью гистограмм и круговых диаграмм;
- Определить, какой график больше всего подходит для текущей задачи.
Используя метод .plot() и структуру DataFrame, вы обнаружили много возможностей для визуализации данных.
Если у вас есть вопросы, пожалуйста, оставьте их в разделе комментариев ниже.

Являюсь администратором нескольких порталов по обучению языков программирования Python, Golang и Kotlin. В составе небольшой команды единомышленников, мы занимаемся популяризацией языков программирования на русскоязычную аудиторию. Большая часть статей была адаптирована нами на русский язык и распространяется бесплатно.
E-mail: vasile.buldumac@ati.utm.md
Образование
Universitatea Tehnică a Moldovei (utm.md)
- 2014 — 2018 Технический Университет Молдовы, ИТ-Инженер. Тема дипломной работы «Автоматизация покупки и продажи криптовалюты используя технический анализ»
- 2018 — 2020 Технический Университет Молдовы, Магистр, Магистерская диссертация «Идентификация человека в киберпространстве по фотографии лица»