
На прошлой неделе, как результат расследования Комитета по Анализу Палаты Представителей, Твиттер выложил список из 2752 аккаунтов, связанных с Российским Агентством Интернет-исследований, которые были связаны с распространением фейковых новостей, в основном направленных на то, чтобы оказать влияние на выборы 2016 года. В данной статье мы рассмотрим, как разделять твиты пользовательских страниц, размещенных с кешированных версий этих страниц (т.к. Twitter заблокировал все аккаунты), с последующим импортом в Neo4j для анализа. Также мы научимся создавать простой интерфейс GraphQL для показа этих данных через GraphQL.
Содержимое:
- Русские Тролли в Твиттере
- Архив Интернета (Internet Archive)
- Поиск Доступных Кэшированных Страниц
- Очистка Профилей в Твиттере
- Импорт В Neo4j
- Графические Запросы
- Основные хештеги
- Самые популярные хештеги
- Топ использованных доменов
- Интерфейс GraphQL
- React приложение
- Подробнее о фабрики троллей (ВИДЕО)
- Подведем Итоги
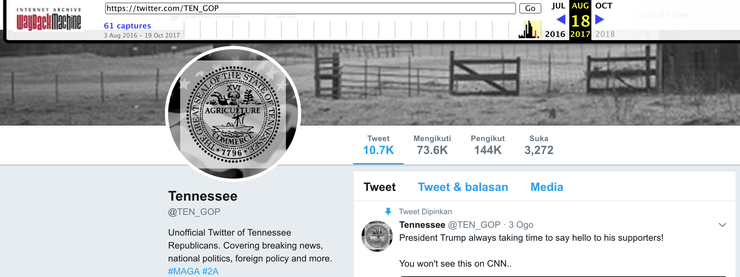
Русские Тролли в Твиттере
Когда представители Твиттера выкладывали список имен и id пользователей, они при этом не предоставили никакой информации (такой как конкретные твиты и количество фолловеров), связанной с этими аккаунтами. Фактически, Твиттер заблокировал эти аккаунты, а это значит, что выложенные твиты удалены с Twitter.com и больше не являются доступными в Twitter API. Анализ этих твитов, выложенных из перечисленных аккаунтов – это первый шаг в понимании того, как аккаунты, управляемые с территории Российской Федерации, повлияли на выборы в США. Так что наш первый шаг – это найти потенциальные источники данных.
Архив Интернета (Internet Archive)
Архив Интернета – это некоммерческая библиотека, которая предоставляет кешированные версии различных сайтов: скрин веб страницы в определенное время, который можно посмотреть в любое время. Один из способов получить удаленные твиты российских троллей – это использовать Интернет Архив для поиска пользовательских страниц в Твиттере, которые вполне могли попасть в кеш.
К примеру, если вы перейдете по ссылке http://web.archive.org/web/20170818065026/https:/twitter.com/TEN_GOP, то увидите страницу Твиттера @TEN_GOP, аккаунт одного из троллей, который был создан для имитации аккаунта Республиканской партии в Теннеси.
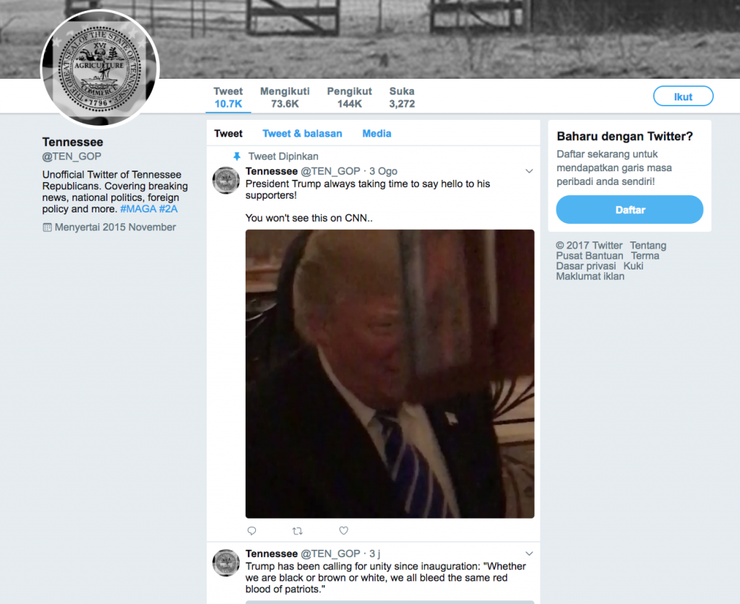
На этом скрине видно несколько последних твитов @TEN_GOP
Поиск Доступных Кэшированных Страниц
Используя перечисленные названия аккаунтов, предоставленных Комитетом Палаты Представителей, мы можем использовать интерфейс Wayback в archive.org, чтобы выяснить, была ли кэширована страница профиля в интернет архиве хотя бы раз. Мы напишем простой скрипт в Python для итерации через список аккаунтов троллей, и проверки в Wayback на наличие доступных кэшированных страниц.
Мы можем сделать это, выполнив запрос:
|
1 |
http://archive.org/wayback/available?url=http://twitter.com/TWITTER_SCREEN_NAME_HERE |
Так мы получим url и timestamp каждого созданного кэша, если таковые имеются. Далее мы выполняем итерацию через список аккаунтов, с последующей проверкой в Wayback на наличие доступных кэшей. Для выполнения HTTP-GET запроса мы используем библиотеку Requests которая прекрасно этим справляется.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import requests items = [] initial = "http://archive.org/wayback/available" # Подбираем каждый twitter аккаунт. with open('./data/twitter_handle_urls.csv') as f: for line in f: params = {'url': line} r = requests.get(initial, params=params) d = r.json() #print(d) items.append(d) # Доступные записи архива записываем в файл. with open('./data/avail_urls.txt', 'w') as f: for item in items: if 'archived_snapshots' in item: if 'closest' in item['archived_snapshots']: f.write(item['archived_snapshots']['closest']['url'] + '\n') |
В результате мы получаем файл twitter_handle_urls.csv, который содержит список ссылок на аккаунты троллей, предоставленных archive.org. К сожалению, было найдено только около сотни аккаунтов, которые были кэшированы в этом архиве. Это лишь малая доля от всего списка, но мы все еще можем очистить твиты этих 100 пользователей.
Очистка Профилей в Твиттере
Теперь мы готовы к очистке HTML от кэш данных интернет архива, чтобы извлечь весь контент, связанный с твиттером. Для этого мы используем пакет BeautifulSoup от Python, который поможет нам извлечь данные Твиттера из HTML. Для начала, используем devtools в Chrome для проверки структуры HTML, и выясним, какие элементы содержат необходимые нам данные:
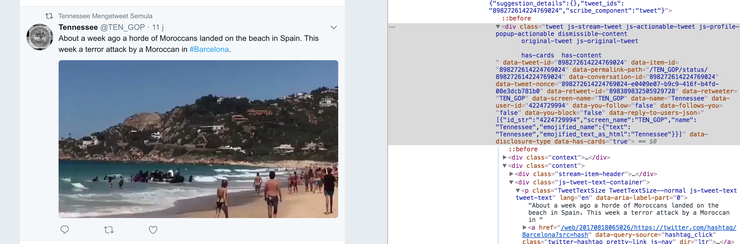
Так как кэш был взят в разные отрезки времени, структура HTML также может быть другой. Нам нужно написать код, который может обрабатывать парсинг разных форматов. Мы нашли две версии аккаунтов в Твиттере в кэшах. Один датируется 2015 годом, другой – 2016-2017.
Пример кода для очистки данных для одной из версий:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
import urllib from bs4 import BeautifulSoup import csv import requests # Тест под новую версию. url = "http://web.archive.org/web/20150603004258/https://twitter.com/AlwaysHungryBae" page = requests.get(url).text soup = BeautifulSoup(page, 'html.parser') tweets = soup.find_all('li', attrs={'data-item-type': 'tweet'}) for t in tweets: tweet_obj = {} tweet_obj['tweet_id'] = t.get("data-item-id") tweet_container = t.find('div', attrs={'class': 'tweet'}) tweet_obj['screen_name'] = tweet_container.get('data-screen-name') tweet_obj['permalink'] = tweet_container.get('data-permalink-path') tweet_content = tweet_container.find('p', attrs={'class': 'tweet-text'}) tweet_obj['tweet_text'] = tweet_content.text tweet_obj['user_id'] = tweet_container.get('data-user-id') tweet_time = tweet_container.find('span', attrs={'class': '_timestamp'}) tweet_obj['timestamp'] = tweet_time.get('data-time-ms') hashtags = tweet_container.find_all('a', attrs={'class': 'twitter-hashtag'}) tweet_obj['hashtags'] = [] tweet_obj['links'] = [] for ht in hashtags: ht_obj = {} ht_obj['tag'] = ht.find('b').text ht_obj['archived_url'] = ht.get('href') tweet_obj['hashtags'].append(ht_obj) links = tweet_container.find_all('a', attrs={'class': 'twitter-timeline-link'}) for li in links: li_obj = {} if li.get('data-expanded-url'): li_obj['url'] = li.get('data-expanded-url') elif li.get('data-resolved-url-large'): li_obj['url'] = li.get('data-resolved-url-large') else: li_obj['url'] = li.text li_obj['archived_url'] = li.get('href') tweet_obj['links'].append(li_obj) print(tweet_obj) |
BeautifulSoup позволяет нам выбирать элементы HTML по определенным атрибутам для сопоставления. Проверив структуру HTML страницы, мы можем заметить, какие куски твитов размещены в разных HTML элементах, их то мы и соберем при помощи BeautifulSoup. Мы создадим массив твит-объектов также, как мы парсировали все твиты на странице
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
{ 'tweet_id': '561931644785811457', 'screen_name': 'AlwaysHungryBae', 'permalink': '/AlwaysHungryBae/status/561931644785811457', 'tweet_text': 'Happy Super Bowl Sunday \n#superbowlfood pic.twitter.com/s6rwMtdLom', 'user_id': '2882130846', 'timestamp': '1422809918000', 'hashtags': [ {'tag': 'superbowlfood', 'archived_url': '/web/20150603004258/https://twitter.com/hashtag/superbowlfood?src=hash' } ], 'links': [ {'url': 'pic.twitter.com/s6rwMtdLom', 'archived_url': 'http://web.archive.org/web/20150603004258/http://t.co/s6rwMtdLom' }, {'url': 'https://pbs.twimg.com/media/B8xh2fFCQAE-vxU.jpg:large', ' archived_url': '//web.archive.org/web/20150603004258/https://twitter.com/AlwaysHungryBae/status/561931644785811457/photo/1' } ] } |
После того, как мы извлекли все твиты, мы можем вписать их в файл json:
|
1 2 3 4 |
# вписываем твиты в файл import json with open('./data/tweets_full.json', 'w') as f: json.dump(tweet_arr, f, ensure_ascii=False, sort_keys=True, indent=4) |
В итоге мы находим примерно 1500 твитов с 187 аккаунтов в Твиттере. Это только маленькая часть всего массива твитов, выложенных троллями. В то же время, такое количество – слишком много. Вычитывать каждый твит самостоятельно займет очень много времени. Мы используем графическую базу данных Neo4j, которая поможет нам понять предоставленные данные. При помощи Neo4j, мы будем в состоянии задавать такие вопросы, как:
- Какие хештеги используются чаще всего?
- Какие домены в URL используются при упоминании Трампа?
Импорт В Neo4j
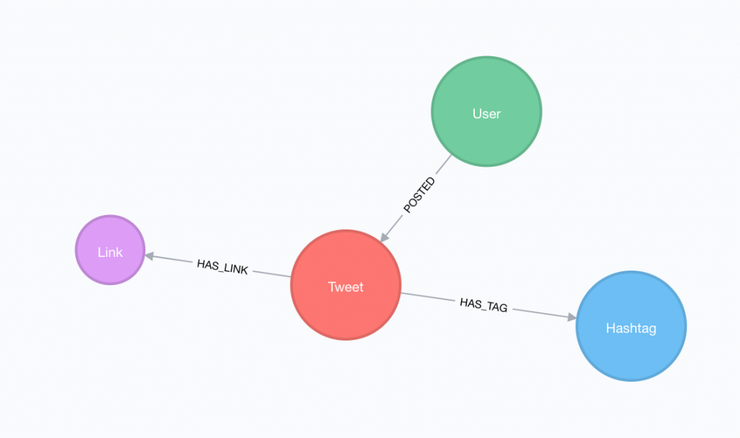
Теперь, так как мы имеем нашу чистую базу данных, мы можем вложить её в Neo4j. Существует несколько способов для импорта данных в Neo4j. Мы выполняем импорт путем загрузки данных JSON и передачи их в качестве параметра для запроса Cypher. Для этого используем драйвер Python для Neo4j. Мы используем простую модель графических данных, после этого обрабатываем хештеги и ссылки в качестве узлов в графике, таким же образом обрабатываем твиты и пользователя, который их постил.
Модель данных
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
from neo4j.v1 import GraphDatabase import json driver = GraphDatabase.driver("bolt://localhost:7687") with open('./data/tweets_full.json') as json_data: tweetArr = json.load(json_data) import_query = ''' WITH $tweetArr AS tweets UNWIND tweets AS tweet MERGE (u:User {user_id: tweet.user_id}) ON CREATE SET u.screen_name = tweet.screen_name MERGE (t:Tweet {tweet_id: tweet.tweet_id}) ON CREATE SET t.text = tweet.tweet_text, t.permalink = tweet.permalink MERGE (u)-[:POSTED]->(t) FOREACH (ht IN tweet.hashtags | MERGE (h:Hashtag {tag: ht.tag }) ON CREATE SET h.archived_url = ht.archived_url MERGE (t)-[:HAS_TAG]->(h) ) FOREACH (link IN tweet.links | MERGE (l:Link {url: link.url}) ON CREATE SET l.archived_url = link.archived_url MERGE (t)-[:HAS_LINK]->(l) ) ''' def add_tweets(tx): tx.run(import_query, tweetArr=tweetArr) with driver.session() as session: session.write_transaction(add_tweets) |
Графические Запросы
Теперь, когда мы обладаем данными в Neo4j, мы можем писать запросы для того, чтобы быстрее понять, о чем пишут тролли.
Интересные Запросы
|
1 2 3 4 5 |
// Твиты @TEN_GOP MATCH (u:User)-[:POSTED]->(t:Tweet)-[:HAS_TAG]->(h:Hashtag) WHERE u.screen_name = "TEN_GOP" OPTIONAL MATCH (t)-[:HAS_LINK]->(l:Link) RETURN * |
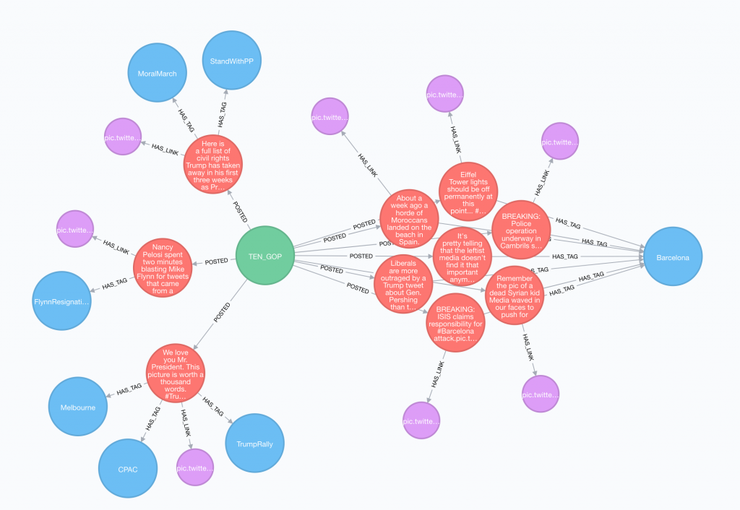
Полная картинка: https://python-scripts.com/wp-content/uploads/2017/11/ten_gop_tweets.png
Основные хештеги
|
1 2 3 4 |
// Основные хештеги MATCH (u:User)-[:POSTED]->(t:Tweet)-[:HAS_TAG]->(ht:Hashtag) RETURN ht.tag AS hashtag, COUNT(*) AS num ORDER BY num DESC LIMIT 10 |
- «JugendmitMerkel» — 90
- «TagderJugend» — 89
- «politics» — 61
- «news» — 30
- «sports» — 28
- «Merkel» — 26
- «ColumbianChemicals» — 25
- «WorldElephantDay» — 22
- «crime» — 21
- «UnitedStatesIn3Words» — 21
Самые популярные хештеги
|
1 2 3 |
MATCH (h1:Hashtag)<-[:HAS_TAG]-(t:Tweet)-[:HAS_TAG]->(h2:Hashtag) WHERE id(h1) < id(h2) RETURN h1.tag, h2.tag, COUNT(*) AS num ORDER BY num DESC LIMIT 15 |
- «JugendmitMerkel«, «TagderJugend» — 89
- «TagderJugend«, «WorldElephantDay» — 22
- «JugendmitMerkel«, «WorldElephantDay» — 22
- «JugendmitMerkel«, «Dschungelkönig» — 21
- «TagderJugend«, «Dschungelkönig» — 21
- «Merkel«, «JugendmitMerkel» — 17
- «Merkel«, «TagderJugend» — 17
- «CDU«, «JugendmitMerkel» — 12
- «CDU«, «TagderJugend» — 12
- «TagderJugend«, «Thailand» — 11
Топ использованных доменов
В простонародье «пруфы» на которые ссылались ссылкой тролли.
|
1 2 3 |
MATCH (t:Tweet)-[:HAS_LINK]->(u:Link) WITH t, replace(replace(u.url, "http://", '' ), "https://", '') AS url RETURN COUNT(t) AS num, head(split(url, "/")) ORDER BY num DESC LIMIT 10 |
- pic.twitter.com — 835
- bit.ly — 120
- pbs.twimg.com — 100
- vk.com — 32
- riafan.ru — 21
- inforeactor.ru — 21
- nevnov.ru — 20
- goodspb.livejournal.com — 17
- www.fox5atlanta.com — 15
Интерфейс GraphQL
В довесок к запросам в Neo4j и прямому использованию Cypher, мы можем также воспользоваться интеграциями GraphQL для того, чтобы легко создать интерфейс для наших твитов.
Для начала, нам потребуется схема GraphQL.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
type Tweet { tweet_id: ID! text: String permalink: String author: User @relation(name: "POSTED", direction: "IN") hashtags: [Hashtag] @relation(name: "HAS_TAG", direction: "OUT") links: [Link] @relation(name: "HAS_LINK", direction: "OUT") } type User { user_id: ID! screen_name: String tweets: [Tweet] @relation(name: "POSTED", direction: "OUT") } type Hashtag { tag: ID! archived_url: String tweets(first: Int): [Tweet] @relation(name: "HAS_TAG", direction: "IN") } type Link { url: ID! archived_url: String } type Query { Hashtag(tag: ID, first: Int, offset: Int): [Hashtag] } |
Наша схема GraphQL определяет типы и доступные поля в данных, а также точки доступа для GraphQL. В данном случае, в качестве простой точки входа мы используем Hashtag, что позволяет нам искать твиты по хештегу.
При помощи интеграции neo4j-graphql-js, схема GraphQL сопоставляет графическую модель базы данных и переводит любой произвольный запрос GraphQL в Cypher, позволяя кому угодно запрашивать данные через интерфейс GraphQL без написания Cypher.
Запуск сервера GraphQL – это всего лишь передача запроса GraphQL к функции, находящейся в resolver.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import {neo4jgraphql} from 'neo4j-graphql-js'; const resolvers = { // корневая точка доступа к GraphQL Query: { Hashtag(object, params, ctx, resolveInfo) { // neo4jgraphql проверяет запрос и схему // GraphQL для генерации простого запроса Cypher // Решение запроса GraphQL. Предполагается, что // экземпляр драйвера Neo4j находится в контексте. return neo4jgraphql(object, params, ctx, resolveInfo); } } }; |
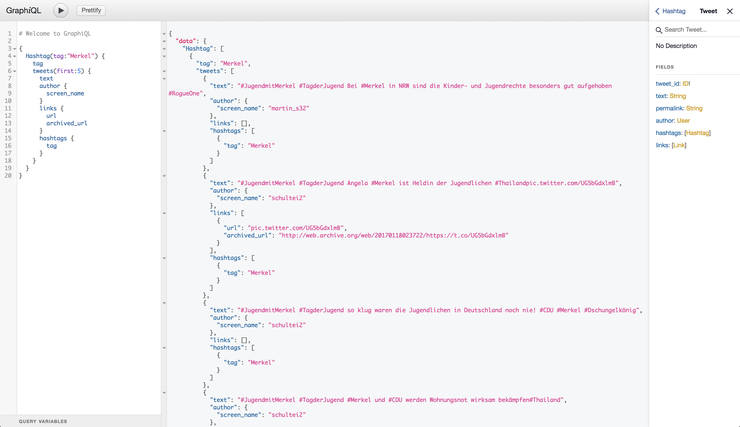
Ссылка на полный размер: https://python-scripts.com/wp-content/uploads/2017/11/graphiql.png
React приложение
Одно из преимуществ использования интерфейса GraphQL в том, что он очень упрощает процесс создания веб и мобильных приложений, которые используют GraphQL. Для того, чтобы поиск данных был легче, мы создали простое приложение React, которые позволяет искать твиты в Neo4j по хештегу.
Здесь мы ищем твиты по запросу #crime и видим, что тролль @OnlineCleveland твитит новости о преступлениях в Огайо, акцентируя на том, что больше всего преступлений происходит именно в Кливленде. Зачем троллю из России твитить о преступлениях в Кливленде аккурат перед выборами? Потому что, когда электорат выбирает политика, который особенно жестко борется с криминалом, он выбирает кого-либо из Республиканской партии…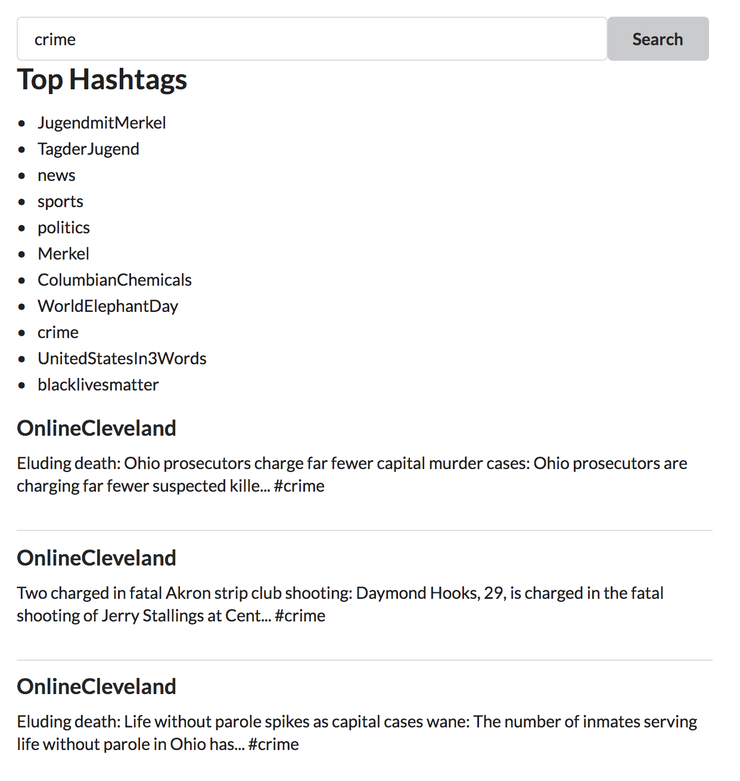
Подробнее о фабрики троллей
Подведем Итоги
В данной статье мы отсортировали и структурировали данные твиттера при помощи Internet Archive, выполнили импорт этих данных в Neo4j для анализа, создали интерфейс GraphQL для отображения данных и простое GRANDstack-приложение, которое позволяет любому быстро найти твиты по хештегу.
Несмотря на то, что мы можем найти только малую долю твитов, которые разместили тролли из российских аккаунтов, мы продолжим поиски способов добычи данных. 

Являюсь администратором нескольких порталов по обучению языков программирования Python, Golang и Kotlin. В составе небольшой команды единомышленников, мы занимаемся популяризацией языков программирования на русскоязычную аудиторию. Большая часть статей была адаптирована нами на русский язык и распространяется бесплатно.
E-mail: vasile.buldumac@ati.utm.md
Образование
Universitatea Tehnică a Moldovei (utm.md)
- 2014 — 2018 Технический Университет Молдовы, ИТ-Инженер. Тема дипломной работы «Автоматизация покупки и продажи криптовалюты используя технический анализ»
- 2018 — 2020 Технический Университет Молдовы, Магистр, Магистерская диссертация «Идентификация человека в киберпространстве по фотографии лица»