
В данной статье вы изучите продвинутую технику веб-автоматизации в Python. Мы используем Selenium с браузером без графического интерфейса, экспортируем отобранные данные в CSV файлы и завернем ваш отобранный код в класс Python.
Содержание
- Мотивация: отслеживаем музыкальные привычки
- Установка и Настройка Selenium
- Пробный запуск браузера в режиме Headless
- Веб-парсинг в Python
- Расширяем потенциал
- Исследуем каталог
- Создание класса
- Собираем структурированные данные
- Что дальше и чему мы научились?
1. Мотивация: отслеживаем музыкальные привычки
Предположим, что вы время от времени слушаете музыку на bandcamp.com или soundcloud и вам хочется вспомнить название песни, которую вы услышали несколько месяцев назад.
Конечно, вы можете покопаться в истории вашего браузера и проверить каждую песню, но это весьма болезненная затея… Все, что вы помните, это то, что вы услышали песню несколько месяцев назад и она в жанре электроника.
«Было бы классно», думаете вы «Если бы у меня запись моей истории прослушиваний. Я мог бы просто взглянуть на электронную музыку, которую я слушал пару месяцев назад и найти эту песню!»
Сегодня мы создадим простой класс Python под названием BandLeader, который подключается к bandcamp.com, стримит музыку из раздела «Найденное» на главной странице, и отслеживает вашу историю прослушиваний.
История прослушиваний будет сохранена на диске в CSV файле. Далее, вы можете в любой момент просматривать CSV файл в вашей любимой программе для работы с таблицами, или даже в Python.
Если у вас есть опыт в веб-парсинга в Python, то вы знакомы с созданием HTTP запросами и использованием API Python для навигации в DOM. Сегодня мы затронем все эти пункты, за одним исключением.
Сегодня вы используете браузер в режиме без графического интерфейса (режим «командной строки») для выполнения запросов HTTP.
Консольный браузер – это обычный веб браузер, который работает без видимого пользовательского интерфейса. Как вы могли догадаться, он может делать больше, чем выполнять запросы: проводить рендер HTML (правда, вы этого не будете видеть), хранить информацию о сессии, даже проводить асинхронные сетевые связи на коде JavaScript.
Если вы хотите автоматизировать современную сеть, консольные браузеры – неотъемлемая часть.
Бесплатный бонус: Скачайте основу проекта Python+Selenium с полным исходным кодом, который вы можете использовать как основу для вашего веб-парсинга в Python и автоматических приложениях.
2. Установка и Настройка Selenium
Первый шаг, перед тем как написать первую строчку кода – это установка Selenium с поддержкой WebDriver для вашего любимого браузера. Далее в статье мы будем работать с Firefox Selenium, но Chrome также будет отлично.
- Установка драйвера geckodriver для Firefox Selenium
- Установка драйвера chromedriver для Chrome Selenium
По выше указанным ссылкам имеется полное описание процесса установки драйверов для Selenium.
Далее, нужно установить Selenium при помощи pip, или как вам удобнее. Если вы создали виртуальное пространство для этого проекта, просто введите:
|
1 |
sudo pip install selenium |
[Если у вас будут вопросы в ходе изучения данной статьи, полный код можно найти на GitHub.]
Время для пробного запуска.
3. Пробный запуск браузера
Чтобы убедиться, что все работает, попробуйте выполнить простой поиск в интернете через DuckDuckGo. Используйте свой предпочитаемый интерпретатор Python и введите:
|
1 2 3 4 5 6 7 8 9 |
from selenium.webdriver import Firefox from selenium.webdriver.firefox.options import Options opts = Options() opts.set_headless() assert opts.headless # без графического интерфейса. browser = Firefox(options=opts) browser.get('https://duckduckgo.com') |
Таким образом, вы только что создали Firefox в режиме консольного приложения (без головы т.е. без графического интерфейса), направленный на https://duckduckgo.com. Вы создали экземпляр «Options» и применили его для активации мода headless в конструкторе Firefox. Это похоже на введение команды firefox – headless в командной строке.
4. Веб-парсинг в Python
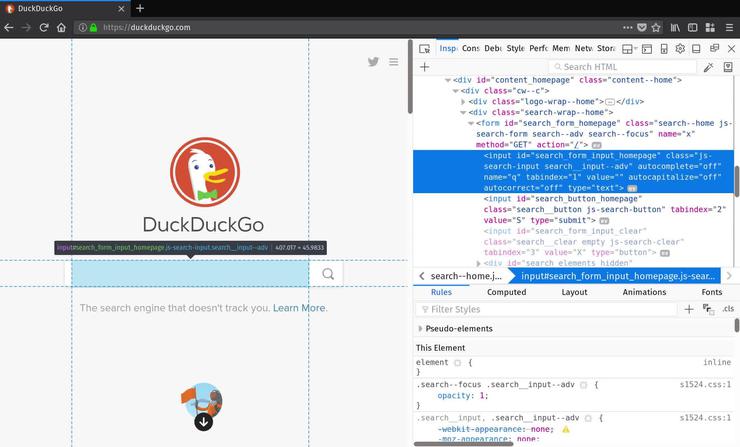
Теперь, когда страница загружена, вы можете запросить DOM при помощи методов, определенных в вашем созданном объекте браузера.
Но откуда мы знаем, что запрашивать? Лучший способ – это открыть ваш веб браузер и использовать его инструменты разработки для исследования содержимого страницы. Сейчас вы можете получить форму поиска для отправки запроса, чтобы выполнить запрос. Проверив главную страницу DuckDuckGo, вы увидите, что элемент поисковой формы<input> имеет атрибут ID «search_form_input_homepage«. Вот, что вам нужно:
|
1 2 3 |
search_form = browser.find_element_by_id('search_form_input_homepage') search_form.send_keys('real python') search_form.submit() |
Вы найдете поисковую форму, используя метод send_keys для заполнения, затем метод submit для выполнения поиска для «Real Python». Вы можете проверить результат:
|
1 2 |
results = browser.find_elements_by_class_name('result') print(results[0].text) |
Результат:
|
1 2 3 |
Real Python - Real Python Get Real Python and get your hands dirty quickly so you spend more time making real applications. Real Python teaches Python and web development from the ground up ... https://realpython.com |
Похоже, все работает. Чтобы избежать появления невидимых экземпляров браузера, нужно закрыть объект браузера перед окончанием сессии в Python:
|
1 2 |
browser.close() quit() |
5. Расширяем потенциал
Вы удостоверились в том, что можете управлять браузером в режиме headless (без головы т.е. без графического интерфейса), используя Python, теперь перейдем к практике.
- Вам нужно включать музыку;
- Вам нужно искать и просматривать музыку;
- Вам нужна информация о проигрываемой музыке.
Для начала, отправимся на https://bandcamp.com и покопаемся в инструментах разработки вашего браузера. Вы увидите большую и яркую кнопку воспроизведения внизу экрана с HTML атрибутом class, который содержит значение «playbutton«. Проверим, как это работает:
|
1 2 3 4 5 6 |
opts = Option() opts.set_headless() browser = Firefox(options=opts) browser.get('https://bandcamp.com') browser.find_element_by_class('playbutton').click() |
Вы должны слышать музыку! Запустите трек и оставьте его, вернитесь обратно в веб браузер. Рядом с кнопкой воспроизведения находится окно поиска. Еще раз, нужно проверить эту секцию. Вы найдете, что каждый видимый и доступный трек имеет значение класса «discover-item«, а каждый объект кликабельный. В Python, проверка выполняется следующим образом:
|
1 2 3 |
tracks = browser.find_elements_by_class_name('discover-item') len(tracks) # 8 tracks[3].click() |
Следующий трек должен воспроизвестись. Это первый шаг в исследовании bandcamp при помощи Python! Вы уделите несколько минут, переключая разные треки в пространстве Python, но скромная библиотека из 8 песен может быстро надоесть.
6. Изучаем каталог
Вернувшись в свой браузер, вы увидите кнопку для изучения всех треков, связанных с окном поиска bandcamp. Сейчас все должно выглядеть знакомым: каждая кнопка имеет значение класса»item-page«. Последняя кнопка — “далее” показывает следующие восемь композиций в каталоге. Нужно выполнить следующее:
|
1 2 3 |
next_button = [e for e in browser.find_elements_by_class_name('item-page') if e.text.lower().find('next') > -1] next_button.click() |
Отлично! Теперь, может вам захочется просмотреть новые треки, и вы подумаете «Я просто перепишу переменные моих треков, так же, как я делал это минуту назад». Но здесь мы с вами столкнемся с хитростями.
Во первых, bandcamp разработали свой сайт так, чтобы пользователям было удобно им пользоваться, а не для скриптов Python для доступа к программному обеспечению. Вызывая next_button.click(), реальный веб браузер отвечает, выполняя какой-нибудь код JavaScript. Если вы попробуете сделать это в своем браузере, то увидите, что некоторое время уходит на эффект анимации каталога песен при прокрутке. Если вы попробуете переписать переменные композиций перед окончанием анимации, то можете получить не все треки, или получить те, которые вам не нужны.
Решение? Вы можете просто заснуть на секунду, или, если вы проделываете работу в оболочке Python, вы, вероятно, даже не заметите этого – в конце концов, на набор данных также уходит время.
Еще один небольшой момент, который можно обнаружить только путем проб и ошибок. Попробуйте запустить такой же код еще раз:
|
1 2 |
tracks = browser.find_elements_by_class_name('discover-item') assert(len(tracks) == 8) # AssertionError |
Вы обнаружите кое-что странное. len(tracks) не равен 8, даже если пачка состоит из восьми треков. Углубившись, вы обнаружите, что ваш список состоит из треков, которые были показаны ранее. Чтобы получить треки, которые будут видны в браузере, нужно сделать небольшую фильтрацию результатов.
Попробовав несколько вариантов, вы решите оставить трек, только если его координата х на странице попадают в определенные рамки содержимого элемента. Контейнер каталога имеет значение класса «discover-results«. Выполним следующее:
|
1 2 3 4 5 6 7 8 9 |
discover_section = self.browser.find_element_by_class_name('discover-results') left_x = discover_section.location['x'] right_x = left_x + discover_section.size['width'] discover_items = browser.find_element_by_class_name('discover_items') tracks = [t for t in discover_items if t.location['x'] >= left_x and t.location['x'] < right_x] assert len(tracks) == 8 |
7. Создание класса
Если вас утомляет переписывать одни и те же команды снова и снова в пространстве Python, вам нужно выгрузить часть из них в модуль. Простейший класс для вашей работы с bandcamp должен выполнять следующие задачи:
- Инициализация headless браузера и выполнить направление на bandcamp;
- Хранение списка доступных треков;
- Поддержка поиска треков;
- Воспроизведение, пауза, переключение треков;
Четыре в одном. Вот простой код:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 |
from selenium.webdriver import Firefox from selenium.webdriver.firefox.options import Options from time import sleep, ctime from collections import namedtuple from threading import Thread from os.path import isfile import csv BANDCAMP_FRONTPAGE='https://bandcamp.com/' class BandLeader(): def __init__(self): # Инициализация браузера. opts = Options() opts.set_headless() self.browser = Firefox(options=opts) self.browser.get(BANDCAMP_FRONTPAGE) # Список треков. self._current_track_number = 1 self.track_list = [] self.tracks() def tracks(self): ''' Запрос страницы для получения списка доступных треков ''' # Режим сна, пока браузер обрабатывает и выполняет все анимации sleep(1) # Получаем хранилище для списка видимых треков. discover_section = self.browser.find_element_by_class_name('discover-results') left_x = discover_section.location['x'] right_x = left_x + discover_section.size['width'] # Фильтруем объекты в списке, чтобы получить только те, которые мы можем включать. discover_items = self.browser.find_elements_by_class_name('discover-item') self.track_list = [t for t in discover_items if t.location['x'] >= left_x and t.location['x'] < right_x] # Вывод доступных треков на экран. for (i,track) in enumerate(self.track_list): print('[{}]'.format(i+1)) lines = track.text.split('\n') print('Album : {}'.format(lines[0])) print('Artist : {}'.format(lines[1])) if len(lines) > 2: print('Genre : {}'.format(lines[2])) def catalogue_pages(self): ''' Вывод доступных в настоящее время страниц в каталоге. ''' print('PAGES') for e in self.browser.find_elements_by_class_name('item-page'): print(e.text) print('') def more_tracks(self,page='next'): ''' Продвижение каталога, обновление списка композиций, мы можем передать число для продвижения любых доступных страниц. ''' next_btn = [e for e in self.browser.find_elements_by_class_name('item-page') if e.text.lower().strip() == str(page)] if next_btn: next_btn[0].click() self.tracks() def play(self,track=None): ''' Запускаем трек. Если не указан номер трека, запустится выбранная только что композиция ''' if track is None: self.browser.find_element_by_class_name('playbutton').click() elif type(track) is int and track <= len(self.track_list) and track >= 1: self._current_track_number = track self.track_list[self._current_track_number - 1].click() def play_next(self): ''' Воспроизводится следующий доступный трек ''' if self._current_track_number < len(self.track_list): self.play(self._current_track_number+1) else: self.more_tracks() self.play(1) def pause(self): ''' Пауза воспроизведения. ''' self.play() |
Весьма удобно. Вы можете импортировать этот код в ваше пространство Python и запустить bandcamp! Но постойте, разве мы не затеяли это все потому, что нам нужно собирать информацию о вашей истории прослушиваний?
8. Собираем структурированные данные
Наша последняя с вами задача, это отслеживать прослушанные вами треки. Как нам это сделать? Что буквально означает слушать что-либо? Если вы пролистываете каталог, переключая треки спустя пару секунд, это считается за прослушивание песни? Скорее всего, нет. Нам нужно включить фактор длительности прослушивания в сбор данных.
Сейчас нам нужно:
- Собрать структурированную информацию о воспроизводимых композициях;
- Хранить базу данных треков;
- Сохранить и восстановить эту базу данных на диск и из диска.
Используем namedtuple для сортировки отслеживаемой вами информации. Кортежи с названиями хороши для показа связки атрибутов без привязки к ним. Это немного похоже на запись базы данных.
|
1 2 3 4 5 6 7 8 |
TrackRec = namedtuple('TrackRec', [ 'title', 'artist', 'artist_url', 'album', 'album_url', 'timestamp' # When you played it ]) |
Чтобы собрать эту информацию, добавьте метод в класс BandLeader. Проверка при помощи инструментов разработки браузера откроет необходимые элементы HTML и атрибуты для выбора всей необходимой информации. Кстати, вам понадобится только информация о недавно прослушанных треках, если в это время музыка воспроизводилась. К счастью, страница плеера добавляет класс «playing» к кнопке воспроизведения, когда музыка играет, и убирает его, когда воспроизведение прекращается. Держа в голове данные нюансы, нужно прописать несколько методов:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
def is_playing(self): ''' Выдает True, если трек воспроизводится в данный момент. ''' playbtn = self.browser.find_element_by_class_name('playbutton') return playbtn.get_attribute('class').find('playing') > -1 def currently_playing(self): ''' Возвращает запись воспроизводимого в данный момент трека или None, если ничего не воспроизводится. ''' try: if self.is_playing(): title = self.browser.find_element_by_class_name('title').text album_detail = self.browser.find_element_by_css_selector('.detail-album > a') album_title = album_detail.text album_url = album_detail.get_attribute('href').split('?')[0] artist_detail = self.browser.find_element_by_css_selector('.detail-artist > a') artist = artist_detail.text artist_url = artist_detail.get_attribute('href').split('?')[0] return TrackRec(title, artist, artist_url, album_title, album_url, ctime()) except Exception as e: print('there was an error: {}'.format(e)) return None |
Для точного измерения, можно также модифицировать метод play для продолжения отслеживания играющего в данный момент трека:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
def play(self, track=None): ''' Запуск трека. Если номер композиции не поддерживается, воспроизведется предыдущий трек. ''' if track is None: self.browser.find_element_by_class_name('playbutton').click() elif type(track) is int and track <= len(self.track_list) and track >= 1: self._current_track_number = track self.track_list[self._current_track_number - 1].click() sleep(0.5) if self.is_playing(): self._current_track_record = self.currently_playing() |
Далее, нам нужно создать какую-либо базу данных. Хотя она может плохо масштабироваться при больших объемах, в простом списке все должно пройти хорошо.
Добавляем строку:
|
1 |
self.database = [] |
В методе инициализации класса BandCamp __init__ . Так как нам нужно дать возможность тому, чтобы прошло определенное время перед входом в объект TrackRec в базе данных, мы используем инструменты threading нашего Python, для запуска отдельных процессов, которые поддерживают базу данных в фоновом режиме.
Мы привяжем метод _maintain() к экземплярам BandLeader, которые запустят раздельный поток. Новый метод будет периодически проверять значение self._current_track_record и добавлять его в базу данных, если это новый трек.
Мы запустим поток, когда класс станет подтвержденным, путем добавления кода в __init__.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
# Новый init. def __init__(self): # Инициализация браузера. opts = Options() opts.set_headless() self.browser = Firefox(options=opts) self.browser.get(BANDCAMP_FRONTPAGE) # Состояние списка треков. self._current_track_number = 1 self.track_list = [] self.tracks() # Состояние базы данных. self.database = [] self._current_track_record = None # Поток поддержки базы данных. self.thread = Thread(target=self._maintain) self.thread.daemon = True # Закрывает поток вместе с основным процессом. self.thread.start() self.tracks() def _maintain(self): while True: self._update_db() sleep(20) # Проверка каждые 20 секунд. def _update_db(self): try: check = (self._current_track_record is not None and (len(self.database) == 0 or self.database[-1] != self._current_track_record) and self.is_playing()) if check: self.database.append(self._current_track_record) except Exception as e: print('error while updating the db: {}'.format(e) |
Если вы никогда не работали с мультипоточным программированием в Python, вы должны с этим ознакомиться! Для нашей нынешней цели, вы можете представить потоки как цикл, который возвращает фоновый режим основного процесса Python (тот, с которым вы напрямую взаимодействуете). Каждые двадцать секунд цикл выполняет небольшую проверку, чтобы увидеть, нужно ли обновить базу данных. Если нужно, он добавляет новую запись. Вполне себе круто.
Самым последним будет сохранение базы данных и восстановление из сохраненных состояний. Используя модуль csv, вы гарантированно будете хранить свою базу данных в очень портативном формате, кроме этого, базу данных можно будет использовать, даже если вы покинете ваш чудесный класс BandLeader 
Метод __init__ снова нужно изменить, на этот раз, для принятия пути файла, в котором вы хотите сохранить базу данных. Вам может понадобиться загрузить эту базу данных, если она доступна, и периодически её сохранять, когда она будет обновлена. Обновления выглядят следующим образом:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
def __init__(self,csvpath=None): self.database_path=csvpath self.database = [] # Загрузка базы данных из диска, если возможно. if isfile(self.database_path): with open(self.database_path, newline='') as dbfile: dbreader = csv.reader(dbfile) next(dbreader) self.database = [TrackRec._make(rec) for rec in dbreader] # ... остальная часть метода __init__ остается неизменной ... # Новый метод save_db. def save_db(self): with open(self.database_path,'w',newline='') as dbfile: dbwriter = csv.writer(dbfile) dbwriter.writerow(list(TrackRec._fields)) for entry in self.database: dbwriter.writerow(list(entry)) # Наконец, добавляем вызов save_db в метод поддержи вашей базы данных. def _update_db(self): try: check = (self._current_track_record is not None and self._current_track_record is not None and (len(self.database) == 0 or self.database[-1] != self._current_track_record) and self.is_playing()) if check: self.database.append(self._current_track_record) self.save_db() except Exception as e: print('error while updating the db: {}'.format(e) |
Ву а ля! Вы можете слушать музыку и хранить запись прослушанных треков. Великолепно.
Кое-что интересное показанном выше коде: использование namedtuple действительно начинает окупаться. При конвертации из формата CSV , вы получаете возможность упорядочивать строки в файле CSV для заполнения строк в объектах TrackRec. Также вы можете создать заглавную строку файла CSV, ссылаясь на атрибут TrackRec._fields. Это одна из причин, по которой использование кортежа имеет смысл во время работы со столбчатыми данными.
Что дальше и чему мы научились?
С этого момента вы умеете делать намного больше! Вот несколько идей, навскидку, которые можно реализовать при помощи суперсилы связки Python + Selenium:
- Вы можете расширить класс BandLeader для навигации по страницам альбомов и воспроизводить найденные в них треки;
- Вы можете создать плейлист на основании своих любимых и наиболее часто прослушиваемых композиций;
- Возможно, вы захотите добавить функцию автоматического воспроизведения;
- Может быть, вам захочется запросить песни по дате, названию или артисту и составить таким образом плейлист.
Здесь вы можете скачать основы проектов «Python + Selenium» со всеми исходными кодами, которые вы можете использовать как фундамент для веб-парсинга и автоматизации приложений.
Вы узнали, что Python может делать то же самое, что и веб-браузер, и даже больше. Вы можете легко прописывать скрипты для контроля экземпляров виртуального браузера, работающего в облаке, создавать ботов, которые могут взаимодействовать с реальными пользователями, или просто заполняют формы! Развивайтесь и автоматизируйте!

Являюсь администратором нескольких порталов по обучению языков программирования Python, Golang и Kotlin. В составе небольшой команды единомышленников, мы занимаемся популяризацией языков программирования на русскоязычную аудиторию. Большая часть статей была адаптирована нами на русский язык и распространяется бесплатно.
E-mail: vasile.buldumac@ati.utm.md
Образование
Universitatea Tehnică a Moldovei (utm.md)
- 2014 — 2018 Технический Университет Молдовы, ИТ-Инженер. Тема дипломной работы «Автоматизация покупки и продажи криптовалюты используя технический анализ»
- 2018 — 2020 Технический Университет Молдовы, Магистр, Магистерская диссертация «Идентификация человека в киберпространстве по фотографии лица»