При написании приложений Python, кэширование играет важную роль. Использование кэша может пригодиться, чтобы избежать перевычисления данных или для получения доступа к медленной базе данных, что может дать хороший рост производительности.
Содержание
- Установка memcached
- Хранение и получение кэшированных значений при помощи Python
- Автоматически истекающие кэшированные данные
- Проверка и настройка
- Итоги
Python предлагает встроенные возможности для кэширования, начиная от простого словаря и заканчивая более сложными структурами данных, типа functools.lru_cache. Последний может кэшировать любой объект при помощи алгоритма Least-Recently Used для ограничения размера кэша.
Однако, эти структуры данных по определению являются локальными для ваших процессов Python. Когда несколько копий вашего приложения работают на большой платформе, использование встроенной в память структуры данных закрывает совместное использование кэшированного контента. Это может быть проблемой для больших и распределенных приложений.
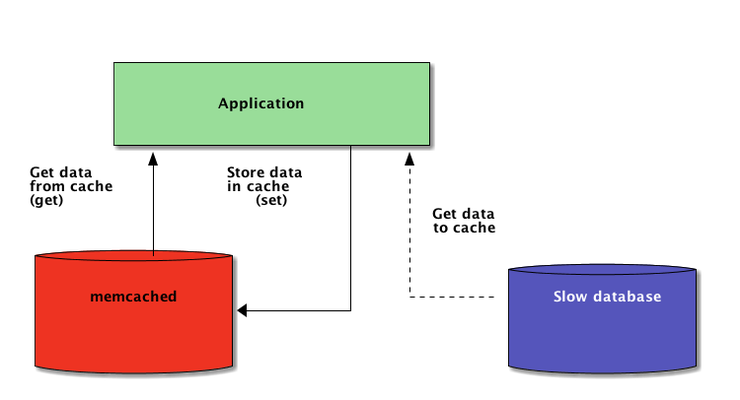
Тем не менее, когда система распределяется по сети, также нужен кэш, который распределен по этой сети. Сегодня существует множество сетевых серверов, которые предоставляют возможность кэширования.
Как вы узнаете далее в этой статье, memcached – отличный вариант для распределенного кэширования. После небольшого введение в базовое использование memcached, вы узнаете кое-что о таких продвинутых шаблонах, как “cache and set” и об использовании резервных кэшей, необходимых для избегания проблем с производительностью холодного кэша.
Установка memcached
memcached работает на многих платформах:
- Если вы работаете на Linux, вы можете установить его, используя apt-get install memcached или yum install memcached. Эти команды установят memcached из преднастроенного пакета, но вы также можете создать memcached из исходника;
- Для macOS самым простым решением является использование Homebrew. Просто запустите brew install memcached после установки пакетного менеджера Homebrew;
- Для Windows вы можете скомпилировать memcached лично, или найти скомпилированные заранее бинарные файлы;
После установки, memcached можно просто запустить, вызвав команду memcached:
|
1 |
memcached |
Перед тем, как вы сможете взаимодействовать с memcached из Python, вам нужно будет установить клиентскую библиотеку memcached. Мы рассмотрим, как это делается в следующей секции, параллельно с базовыми операциями доступа к кэшу.
Хранение и Получение Кэшированных Значений при Помощи Python
Если вы не пользовались memcached ранее – ничего страшного, в нем очень легко разобраться. По сути, он предоставляет гигантский словарь, который доступный в сети. Этот словарь имеет несколько свойств, которые отличаются от классических словарей Python, а именно:
- Ключи и значения должны быть байтами;
- Ключи и значения автоматически удаляются по истечению времени;
Следовательно, две базовые операции для взаимодействия с memcached – установка и получение. Как вы могли догадаться, они используются для назначения значения ключу, или получение значение из ключа соответственно.
Я предпочитаю библиотеку pymemcache для взаимодействия с memcached, рекомендую её и вам. Её легко установить при помощи pip:
|
1 |
pip install pymemcache |
Следующий код показывает, как вы можете подключиться к memcached и использовать его как распределенный сетевой кэш в вашем приложении Python:
|
1 2 3 4 5 6 7 8 9 10 |
from pymemcache.client import base # Не забудьте запустить memcached перед запуском следующей строки: client = base.Client(('localhost', 11211)) # После того как клиент инстанцирован, вы можете получить доступ к кэшу: client.set('some_key', 'some value') # Получаем установленные ранее данные еще раз: client.get('some_key') # 'some value' |
Протокол сети memcached очень простой и работает невероятно быстро, это делает его полезным для хранения данных, которые (в противном случае) замедлили бы получение данных из каноничного исходника или при повторном вычислении.
Несмотря на то, что данный пример достаточно простой, он позволяет хранить картежи ключей\значений в сети и получить к ним доступ через несколько запущенных, распределенных копий вашего приложения. Это просто и эффективно одновременно. И это только первый шаг в сторону оптимизации вашего приложения.
Автоматически истекающие кэшированные данные
Храня данные в memcached, вы можете настроить время истечения – максимальное количество секунд, которое memcached может хранить ключ и значение. После этой отметки, memcached автоматически удаляет ключи из кэша.
На какое время следует устанавливать этот таймер? Нет никаких волшебных цифр для этого временного отрезка, и все зависит исключительно от типа данных и приложения, с которым вы работаете. Это может быть от нескольких секунд, до нескольких часов.
Недействительность кэша означает, когда кэш будет удален в связи с отсутствием синхронизации с актуальными данными. Ваше приложение должно обрабатывать данную операцию. Особенно, если представленные данные слишком старые, или их нужно избегать.
Еще раз, нет универсального рецепта. Все зависит от типа приложение, которое вы создаете. Однако, существует несколько отдельных случаев, которые нужно обработать. Их мы еще не рассматривали в данном примере.
Сервер кэширования не может бесконечно расти, так как память – ограниченный ресурс. Следовательно, ключи будут устранены сервером кэширования, как только ему понадобится больше места для хранения других штук.
Некоторые ключи могут также исчезнуть в связи с их истекшим сроком действия. В таких случаях вы теряете данные, и нужно снова выполнять запрос в каноничном источнике данных.
Это все звучит сложнее, чем оно есть на самом деле. Вы можете спокойно работать со следующим шаблоном, когда используете memcached в Python:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
from pymemcache.client import base def do_some_query(): # Замените фактический код запроса на базу данных # на удаленный REST API и т.д. return 42 # Не забудьте запустить memcached перед запуском этого кода: client = base.Client(('localhost', 11211)) result = client.get('some_key') if result is None: # Кэш пустой, необходимо получить значение # из источника: result = do_some_query() # Кэширование результата в следующий раз: client.set('some_key', result) # Вне зависимости от того, нужно нам обновить кэш или нет # с этого момента вы можете работать с данными # хранящимися в переменной result print(result) |
Обратите внимание: обработка пропавших ключей это обязательно в нормальных операциях очистки. Также обязательно обрабатывать сценарий холодного кэша. Другими словами, когда memcached только что был запущен. В этом случае, кэш будет абсолютно пустым и ему нужно быть полностью восстановленным по одному запросу за раз.
Это значит, что вам нужно рассматривать любые кэшированные данные как эфемерные. Также вам не следует ожидать того, что в кэше будут те же данные, которые вы вносили ранее.
Разогреваем Холодный Кэш
Некоторые сценарии холодного кэша не могут быть предотвращены, например, крэш memcached. Но некоторые можно, например, миграция на новый сервер memcached.
Когда возможно предугадать выполнение сценария холодного кэша – этого лучше избежать. Кэш, который нужно заполнить еще раз, может действовать неожиданно. Когда исходное хранилище кэшированных данных затронут все пользователи кэша, имеющие недостаток кэшированных данных (также известно, как проблема табуна).
pymemcache предоставляет класс, под названием FallbackClient, который помогает при реализации данного сценария. Давайте посмотрим, как это выглядит:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
from pymemcache.client import base from pymemcache import fallback def do_some_query(): # Замена фактического кода запроса базой данной # на удаленный REST API, и т.д. return 42 # Устанавливаем ignore_exc=True для возможности остановки работы # старого кэша перед устранением его использования # программой, если необходимо old_cache = base.Client(('localhost', 11211), ignore_exc=True) new_cache = base.Client(('localhost', 11212)) client = fallback.FallbackClient((new_cache, old_cache)) result = client.get('some_key') if result is None: # Кэш пустой, нужно дать значение # из исходника result = do_some_query() # Кэширование результата на следующий раз: client.set('some_key', result) print(result) |
FallbackClient запрашивает старый кэш в его конструкторе по порядку. В этом случае, новый сервер кэширования будет всегда запрашиваться первым, а в случае с пропажей кэша, будет запрошен старый, избегая, таким образом, возврат к первичному источнику данных.
Если какой-либо ключ установлен, он будет установлен только в новом кэше. После некоторого времени, старый кэш может быть устранен, и FallbackClient можно заменить согласно с клиентом new_cache.
Проверка и Настройка (Check And Set)
При взаимодействии с удаленным кэшем, возвращается проблема параллелизма: у нас может быть несколько клиентов, пытающихся получить доступ к одному и тому же ключу в одно и то же время. memcached позволяет проверить и настроить операцию, что поможет в решении этой проблемы.
Простейший пример – это приложение, которому нужно подсчитать количество пользователей, которые им пользуется. Каждый раз, когда пользователь подключается, счетчик увеличивается на 1. Используя memcached, простейшее выполнение будет выглядеть следующим образом:
|
1 2 3 4 5 6 7 |
def on_visit(client): result = client.get('visitors') if result is None: result = 1 else: result += 1 client.set('visitors', result) |
Однако, что, если два экземпляра приложения попытаются обновить этот счетчик одновременно?
Первый вызов client.get(‘visitors’) должен вернуть аналогичное количество пользователей каждому приложению, скажем, 42. Затем оба приложения добавляют в счетчик 1, подсчитывая, таким образом, 43 пользователя, и указывают количество пользователей как 43. Это число – неправильное, и результат должен быть 44. То есть 42 + 1 + 1.
Для решения проблемы параллелизма отлично подойдет операция CAS в нашем memcached. Следующий отрезок кода содержит правильное решение:
|
1 2 3 4 5 6 7 8 9 |
def on_visit(client): while True: result, cas = client.gets('visitors') if result is None: result = 1 else: result += 1 if client.cas('visitors', result, cas): break |
Метод gets возвращает значение, также, как метод get, но мы получаем еще и значение CAS.
То, что в этом значении, не является релевантным, но используется для вызова следующего метода cas. Этот метод аналогичен операции настройки, за исключением того, что он не справляется, если значение поменялось после операции метода gets. В случае успеха – цикл разрывается. В противном случае операция начнется с самого начала.
В сценарии, где два экземпляра одного и того же приложения пытаются обновить счетчик в одно и то же время, только у одного выйдет перевести значение с 42 до 43. Второй экземпляр получает значение False после вызова client.cas, и должен повторить цикл. Это извлечет 43 как фактическое значение в этот раз, и приложение увеличит счетчик до 44, а вызов cas пройдет удачно. Таким образом, мы решили нашу проблему параллелизма.
Увеличение счетчика – это интересный пример, в котором можно объяснить, как работает CAS в его простоте. Однако, memcached также предоставляет методы incr и decr для увеличения или уменьшения целого числа в одном запросе, вместо нескольких запросов gets/cas. В реальных приложениях gets и cas используются в более сложных типах данных или операциях.
Большинство удаленных кэширующих серверов и хранилищ данных предоставляют такой механизм для избегания проблем параллелизма. Крайне важно иметь представление о таких случаях, чтобы использовать предоставляемые функции правильно.
Подведем итоги кэширования
В данной статье проиллюстрированы простые техники, показывающие, как легко использовать memcached для ускорения производительности вашего приложение Python.
Просто используя две базовые операции — “set” и “get”, вы можете ускорять поиск данных, или избегать перерасчета результатов снова и снова. При помощи memcached вы можете распределять кэш в большом количестве дистрибуторских узлов.
Другие, более сложные шаблоны, которые были показаны в данной статье, вроде операции CAS (Check And Set), позволяют вам обновлять данные, хранящиеся в кэше, параллельно через несколько потоков Python или процессов и избежать повреждения данных.
Если вам интересно узнать больше о расширенных техниках написания быстрых и эффективных приложений Python, вы можете ознакомиться с другими нашими статьями. Мы рассматриваем различные продвинутые темы для написания и работы в приложениях Python.

Являюсь администратором нескольких порталов по обучению языков программирования Python, Golang и Kotlin. В составе небольшой команды единомышленников, мы занимаемся популяризацией языков программирования на русскоязычную аудиторию. Большая часть статей была адаптирована нами на русский язык и распространяется бесплатно.
E-mail: vasile.buldumac@ati.utm.md
Образование
Universitatea Tehnică a Moldovei (utm.md)
- 2014 — 2018 Технический Университет Молдовы, ИТ-Инженер. Тема дипломной работы «Автоматизация покупки и продажи криптовалюты используя технический анализ»
- 2018 — 2020 Технический Университет Молдовы, Магистр, Магистерская диссертация «Идентификация человека в киберпространстве по фотографии лица»