Пакет NumPy является незаменимым помощником Python. Он тянет на себе анализ данных, машинное обучение и научные вычисления, а также существенно облегчает обработку векторов и матриц. Некоторые ведущие пакеты Python используют NumPy как основной элемент своей инфраструктуры. К их числу относятся scikit-learn, SciPy, pandas и tensorflow. Помимо возможности разобрать по косточкам числовые данные, умение работать с NumPy дает значительное преимущество при отладке более сложных сценариев библиотек.
Содержание
- Создание массивов NumPy
- Арифметические операции над массивами NumPy
- Индексация массива NumPy
- Агрегирование в NumPy
- Создание матриц NumPy на примерах
- Арифметические операции над матрицами NumPy
- dot() Скалярное произведение NumPy
- Индексация матрицы NumPy
- Агрегирование матриц NumPy
- Транспонирование и изменение формы матриц в numpy
- Примеры работы с NumPy
- Таблицы NumPy — примеры использования таблиц
- Аудио и временные ряды в NumPy
- Обработка изображений в NumPy
- Обработка текста в NumPy на примерах

В данной статье будут рассмотрены основные способы использования NumPy на примерах, а также типы представления данных (таблицы, картинки, текст и так далее) перед их последующей подачей модели машинного обучения.
|
1 |
import numpy as np |
Создание массивов NumPy
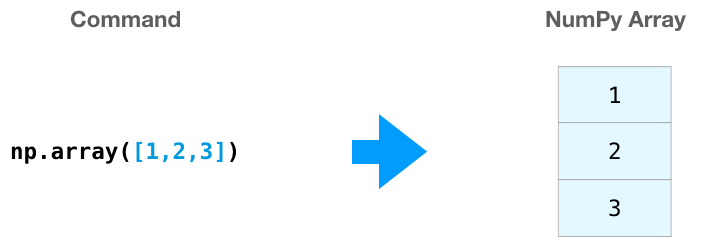
Можно создать массив NumPy (он же ndarray), передав ему список Python, используя np.array(). В данном случае Python создает массив, который выглядит следующим образом:
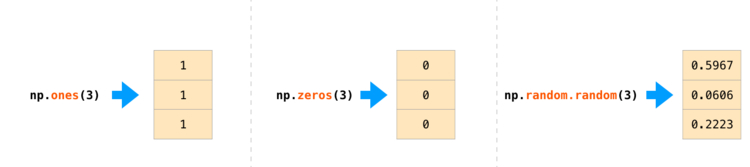
Нередки случаи, когда необходимо, чтобы NumPy инициализировал значения массива.
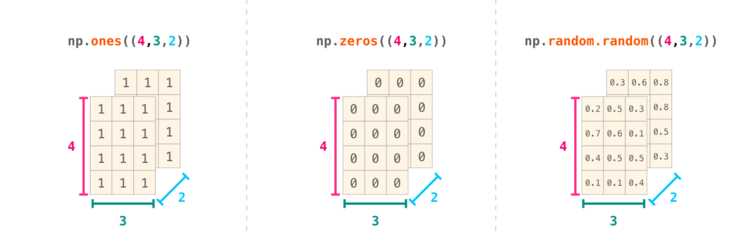
Для этого NumPy использует такие методы, как ones(), zeros() и random.random(). Требуется просто передать им количество элементов, которые необходимо сгенерировать:
После создания массивов можно манипулировать ими довольно любопытными способами.
Арифметические операции над массивами NumPy
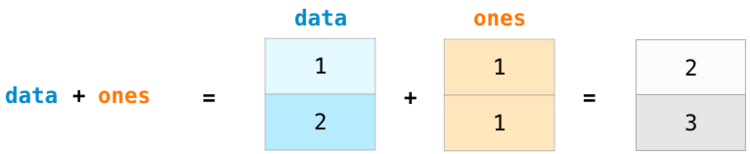
Создадим два массива NumPy и продемонстрируем выгоду их использования.
Массивы будут называться data и ones:

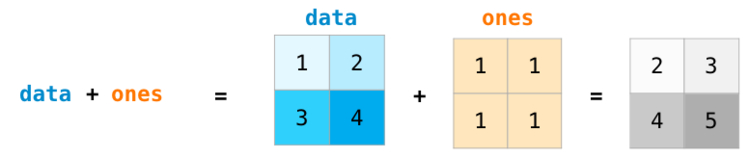
При сложении массивов складываются значения каждого ряда. Это сделать очень просто, достаточно написать data + ones:
Новичкам может прийтись по душе тот факт, что использование абстракций подобного рода не требует написания циклов for с вычислениями. Это отличная абстракция, которая позволяет оценить поставленную задачу на более высоком уровне.
Помимо сложения, здесь также можно выполнить следующие простые арифметические операции:

Довольно часто требуется выполнить какую-то арифметическую операцию между массивом и простым числом. Ее также можно назвать операцией между вектором и скалярной величиной. К примеру, предположим, в массиве указано расстояние в милях, и его нужно перевести в километры. Для этого нужно выполнить операцию data * 1.6:

Как можно увидеть в примере выше, NumPy сам понял, что умножить на указанное число нужно каждый элемент массива. Данный концепт называется трансляцией, или broadcating. Трансляция бывает весьма полезна.
Индексация массива NumPy
Массив NumPy можно разделить на части и присвоить им индексы. Принцип работы похож на то, как это происходит со списками Python.

Агрегирование в NumPy
Дополнительным преимуществом NumPy является наличие в нем функций агрегирования:

Функциями min(), max() и sum() дело не ограничивается.
К примеру:
mean()позволяет получить среднее арифметическое;prod()выдает результат умножения всех элементов;stdнужно для среднеквадратического отклонения.
Это лишь небольшая часть довольно обширного списка функций агрегирования в NumPy.
Использование нескольких размерностей NumPy
Все перечисленные выше примеры касаются векторов одной размерности. Главным преимуществом NumPy является его способность использовать отмеченные операции с любым количеством размерностей.
Создание матриц NumPy на примерах
Созданные в следующей форме списки из списков Python можно передать NumPy. Он создаст матрицу, которая будет представлять данные списки:
|
1 |
np.array([[1,2],[3,4]]) |

Упомянутые ранее методы ones(), zeros() и random.random() можно использовать так долго, как того требует проект.
Достаточно только добавить им кортеж, в котором будут указаны размерности матрицы, которую мы создаем.

Арифметические операции над матрицами NumPy
Матрицы можно складывать и умножать при помощи арифметических операторов (+ - * /). Стоит, однако, помнить, что матрицы должны быть одного и того же размера. NumPy в данном случае использует операции координат:
Арифметические операции над матрицами разных размеров возможны в том случае, если размерность одной из матриц равно одному. Это значит, что в матрице только один столбец или один ряд. В таком случае для выполнения операции NumPy будет использовать правила трансляции:

dot() Скалярное произведение NumPy
Главное различие с обычными арифметическими операциями здесь в том, что при умножении матриц используется скалярное произведение. В NumPy каждая матрица может использовать метод dot(). Он применяется для проведения скалярных операций с рассматриваемыми матрицами:

На изображении выше под каждой фигурой указана ее размерность. Это сделано с целью отметить, что размерности обеих матриц должны совпадать с той стороны, где они соприкасаются. Визуально представить данную операцию можно следующим образом:

Индексация матрицы NumPy
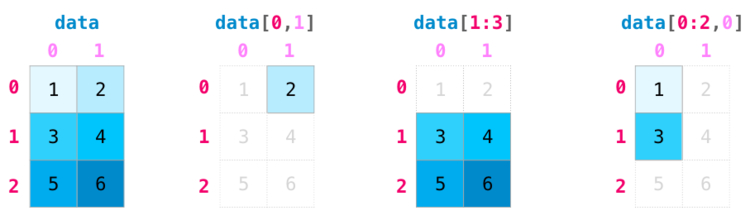
Операции индексации и деления незаменимы, когда дело доходит до манипуляции с матрицами:
Агрегирование матриц NumPy
Агрегирование матриц происходит точно так же, как агрегирование векторов:

Используя параметр axis, можно агрегировать не только все значения внутри матрицы, но и значения за столбцами или рядами.

Транспонирование и изменение формы матриц в numpy
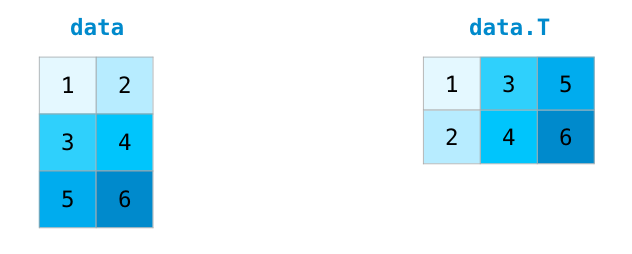
Нередки случаи, когда нужно повернуть матрицу. Это может потребоваться при вычислении скалярного произведения двух матриц. Тогда возникает необходимость наличия совпадающих размерностей. У массивов NumPy есть полезное свойство под названием T, что отвечает за транспонирование матрицы.
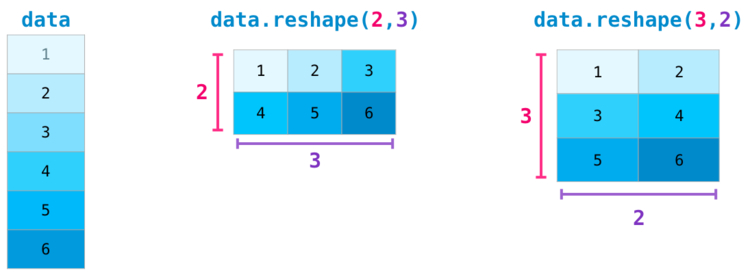
Некоторые более сложные ситуации требуют возможности переключения между размерностями рассматриваемой матрицы. Это типично для приложений с машинным обучением, где некая модель может запросить определенную форму вывода, которая является отличной от формы начального набора данных. В таких ситуациях пригодится метод reshape() из NumPy. Здесь от вас требуется только передать новые размерности для матрицы. Для размерности вы можете передать -1, и NumPy выведет ее верное значение, опираясь на данные рассматриваемой матрицы:
Еще больше размерностей NumPy
NumPy может произвести все вышеперечисленные операции для любого количества размерностей. Структура данных, расположенных центрально, называется ndarray, или n-мерным массивом.

В большинстве случаев для указания новой размерности требуется просто добавить запятую к параметрам функции NumPy:
На заметку: Стоит иметь в виду, что при выводе 3-мерного массива NumPy результат, представленный в виде текста, выглядит иначе, нежели показано в примере выше. Порядок вывода n-мерного массива NumPy следующий — последняя ось зацикливается быстрее всего, а первая медленнее всего. Это значит, что вывод
np.ones((4,3,2))будет иметь вид:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
array([[[1., 1.], [1., 1.], [1., 1.]], [[1., 1.], [1., 1.], [1., 1.]], [[1., 1.], [1., 1.], [1., 1.]], [[1., 1.], [1., 1.], [1., 1.]]]) |
Примеры работы с NumPy
Подытожим все вышесказанное. Вот несколько примеров полезных инструментов NumPy, которые могут значительно облегчить процесс написания кода.
Математические формулы NumPy
Необходимость внедрения математических формул, которые будут работать с матрицами и векторами, является главной причиной использования NumPy. Именно поэтому NumPy пользуется большой популярностью среди представителей науки. В качестве примера рассмотрим формулу среднеквадратичной ошибки, которая является центральной для контролируемых моделей машинного обучения, что решают проблемы регрессии:
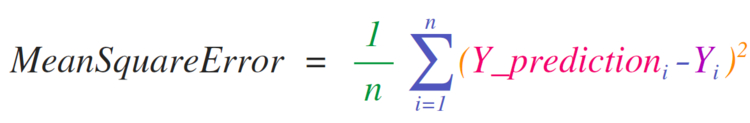
Реализовать данную формулу в NumPy довольно легко:
![]()
Главное достоинство NumPy в том, что его не заботит, если predictions и labels содержат одно или тысячи значение (до тех пор, пока они оба одного размера). Рассмотрим пример, последовательно изучив четыре операции в следующей строке кода:

У обоих векторов predictions и labels по три значения. Это значит, что в данном случае n равно трем. После выполнения указанного выше вычитания мы получим значения, которые будут выглядеть следующим образом:

Затем мы можем возвести значения вектора в квадрат:

Теперь мы вычисляем эти значения:

Таким образом мы получаем значение ошибки некого прогноза и score за качество модели.
Представление данных NumPy
Задумайтесь о всех тех типах данных, которыми вам понадобится оперировать, создавая различные модели работы (электронные таблицы, изображения, аудио и так далее). Очень многие типы могут быть представлены как n-мерные массивы:
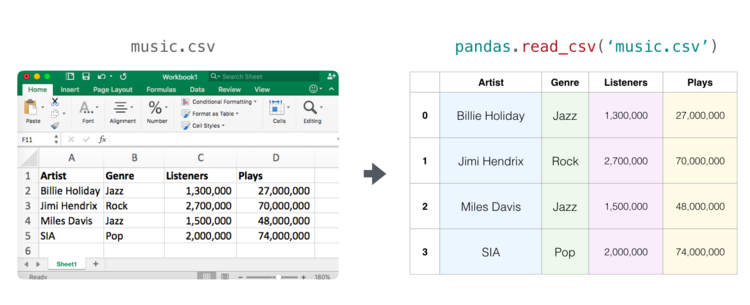
Таблицы NumPy — примеры использования таблиц
Таблица значений является двумерной матрицей. Каждый лист таблицы может быть отдельной переменной. Для работы с таблицами в Python чаще всего используется pandas.DataFrame, что задействует NumPy и строит поверх него.
Аудио и временные ряды в NumPy
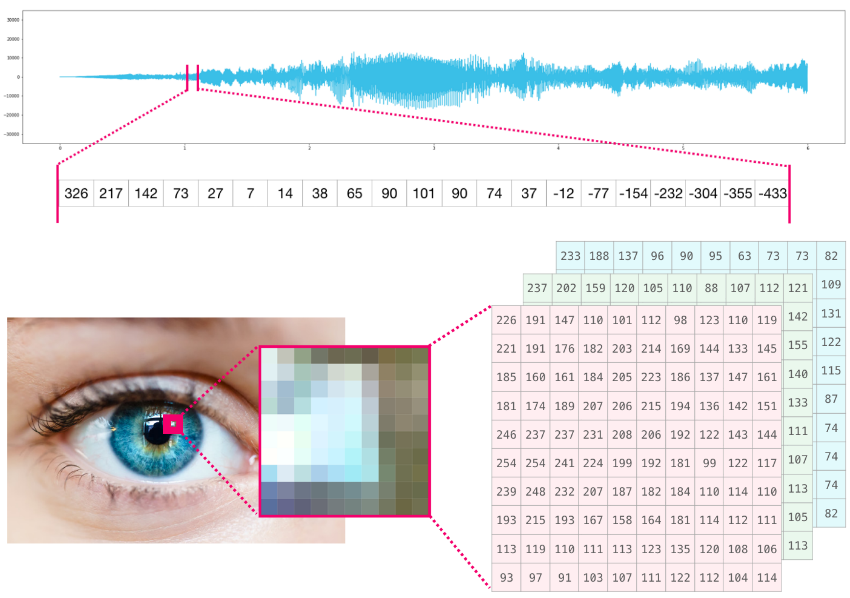
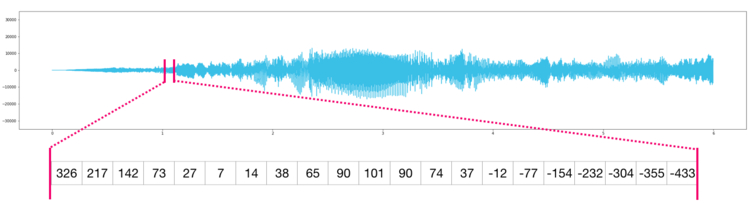
По сути аудио файл — это одномерный массив семплов. Каждый семпл представляет собой число, которое является крошечным фрагментов аудио сигнала. Аудио CD-качества может содержать 44 100 семплов в секунду, каждый из которых является целым числом в промежутке между -32767 и 32768. Это значит, что десятисекундный WAVE-файл CD-качества можно поместить в массив NumPy длиной в 10 * 44 100 = 441 000 семплов.
Хотите извлечь первую секунду аудио? Просто загрузите файл в массив NumPy под названием audio, после чего получите audio[: 44100].
Фрагмент аудио файла выглядит следующим образом:
То же самое касается данных временных рядов, например, изменения стоимости акций со временем.
Обработка изображений в NumPy
Изображение является матрицей пикселей по размеру (высота х ширина).
Если изображение черно-белое, то есть представленное в полутонах, каждый пиксель может быть представлен как единственное число. Обычно между 0 (черный) и 255 (белый). Хотите обрезать квадрат размером 10 х 10 пикселей в верхнем левом углу картинки? Просто попросите в NumPy image[:10, :10].
Вот как выглядит фрагмент изображения:
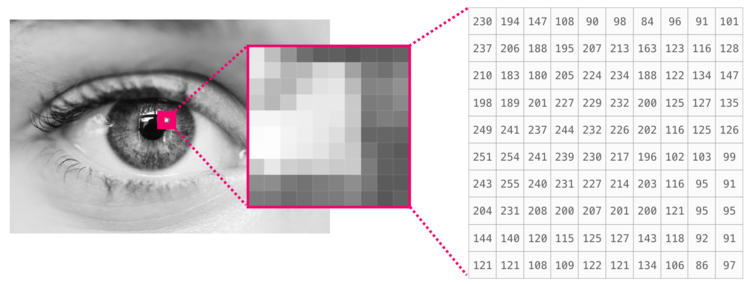
Если изображение цветное, каждый пиксель представлен тремя числами. Здесь за основу берется цветовая модель RGB — красный (R), зеленый (G) и синий (B).
В данном случае нам понадобится третья размерность, так как каждая клетка вмещает только одно число. Таким образом, цветная картинка будет представлена массивом ndarray с размерностями: (высота х ширина х 3).

Обработка текста в NumPy на примерах
Когда дело доходит до текста, подход несколько меняется. Цифровое представление текста предполагает создание некого python словаря, то есть инвентаря всех уникальных слов, которые бы распознавались моделью, а также векторно (embedding step). Попробуем представить в цифровой форме цитату из стихотворения арабского поэта Антара ибн Шаддада, переведенную на английский язык:
“Have the bards who preceded me left any theme unsung?”
Перед переводом данного предложения в нужную цифровую форму модель должна будет проанализировать огромное количество текста. Здесь можно обработать небольшой набор данный, после чего использовать его для создания словаря из 71 290 слов.

Предложение может быть разбито на массив токенов, что будут словами или частями слов в зависимости от установленных общих правил:
![]()
Затем в данной таблице словаря вместо каждого слова мы ставим его id:
![]()
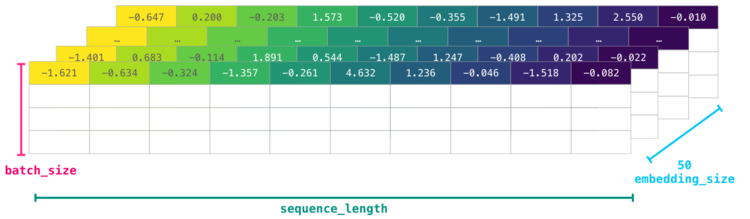
Однако данные id все еще не обладают достаточным количеством информации о модели как таковой. Поэтому перед передачей последовательности слов в модель токены/слова должны быть заменены их векторными представлениями. В данном случае используется 50-мерное векторное представление Word2vec.

Здесь ясно видно, что у массива NumPy есть несколько размерностей [embedding_dimension x sequence_length]. На практике все выглядит несколько иначе, однако данное визуальное представление более понятно для разъяснения общих принципов работы.
Для лучшей производительности модели глубокого обучения обычно сохраняют первую размерность для пакета. Это происходит из-за того, что тренировка модели происходит быстрее, если несколько примеров проходят тренировку параллельно. Здесь особенно полезным будет reshape(). Например, такая модель, как BERT, будет ожидать ввода в форме: [batch_size, sequence_length, embedding_size].
Теперь мы получили числовой том, с которым модель может работать и делать полезные вещи. Некоторые строки остались пустыми, однако они могут быть заполнены другими примерами, на которых модель может тренироваться или делать прогнозы.
(На заметку: Поэма, строчку из которой мы использовали в примере, увековечила своего автора в веках. Будучи незаконнорожденным сыном главы племени от рабыни, Антара ибн Шаддан мастерски владел языком поэзии. Вокруг исторической фигуры поэта сложились мифы и легенды, а его стихи стали частью классической арабской литературы).

Являюсь администратором нескольких порталов по обучению языков программирования Python, Golang и Kotlin. В составе небольшой команды единомышленников, мы занимаемся популяризацией языков программирования на русскоязычную аудиторию. Большая часть статей была адаптирована нами на русский язык и распространяется бесплатно.
E-mail: vasile.buldumac@ati.utm.md
Образование
Universitatea Tehnică a Moldovei (utm.md)
- 2014 — 2018 Технический Университет Молдовы, ИТ-Инженер. Тема дипломной работы «Автоматизация покупки и продажи криптовалюты используя технический анализ»
- 2018 — 2020 Технический Университет Молдовы, Магистр, Магистерская диссертация «Идентификация человека в киберпространстве по фотографии лица»