
Scrapy является фреймворком, что прекрасно подойдет для скрапинга веб сайтов. Он без особых проблем справляется с самыми популярными случаями веб скрапинга, среди которых:
- Многопоточность;
- Веб-краулер для перехода от ссылке к ссылки;
- Извлечение данных;
- Проверка данных;
- Сохранение в другой формат/базу данных;
- Многое другое.
Главное отличие между Scrapy и другими популярными библиотеками, такими как Requests или BeautifulSoup, заключается в том, что он позволяет решать обычные задачи веб скрапинга при помощи самых элегантных методов.
К недостаткам Scrapy можно отнести и тот факт, что начать ему обучаться бывает довольно сложно. Но мы ведь для этого здесь и собрались 
В данном руководстве мы создадим два веб скрапера. Один будет простым, его задачей станет извлечение данных со страницы продукта онлайн магазина. Второй будет несколько сложнее. Его назначением будет скрапинг целого каталога сайта онлайн магазина.
Обзор основ работы со Scrapy
Установить Scrapy можно через pip. Но будьте внимательны. В документации Scrapy настоятельно рекомендуется устанавливать его в специальной виртуальной среде во избежание конфликтов с пакетами вашей системы.
Я использую Virtualenv и Virtualenvwrapper:
|
1 2 |
python3.7 -m venv scrapy_env source scrapy_env/bin/activate |
После активации виртуальной среды, у вас в терминале должен изменится ввод команд. Например:
|
1 |
(scrapy_env):~$ pip list |
Теперь у вас изолированная среда разработки, можете установить в ней нужные пакеты:
|
1 |
pip install Scrapy |
Теперь можно создать cкрапи проект с помощью этой команды:
|
1 |
scrapy startproject product_scraper |
Это создаст все необходимые файлы для проекта:
|
1 2 3 4 5 6 7 8 9 10 11 |
├── product_scraper │ ├── __init__.py │ ├── __pycache__ │ ├── items.py │ ├── middlewares.py │ ├── pipelines.py │ ├── settings.py │ └── spiders │ ├── __init__.py │ └── __pycache__ └── scrapy.cfg |
Далее представлено краткое описание файлов и папок:
- items.py является моделью для извлеченных данных. Вы можете определить настраиваемую модель (например
Product), что унаследует классItem. - middlewares.py
Middlewareиспользуется для изменения жизненного цикла запросов и ответов. Например, вы можете создать промежуточное программное обеспечение для ротации пользовательских агентов или использовать API вроде ScrapingBee вместо того, чтобы выполнять запросы самостоятельно. - pipelines.py В скрапи, пайплайны, или конвейеры используются для обработки извлеченных данных, очистки HTML, проверки данных, их экспорта в пользовательский формат или сохранения в базе данных.
- /spiders является папкой, содержащей классы
Spider. В ScrapySpiderявляются классом, которые определяют, как должен быть проведен скрапинг сайта, в том числе по какой ссылке следовать и как извлечь данные для этих ссылок. - scrapy.cfg является файлом конфигурации для изменения некоторых настроек.
Скрапинг продуктов из интернет магазина на Python
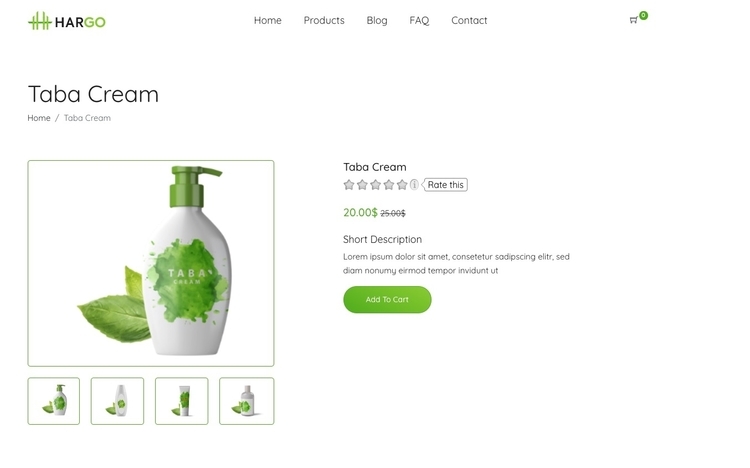
В данном примере будет проведен скрапинг одного продукта с фиктивного сайта онлайн магазина. Вот первый товар, скрапингом которого мы займемся:
|
1 |
https://clever-lichterman-044f16.netlify.com/products/taba-cream.1/ |
Мы извлечем название продукта, изображение, цену и описание.
Оболочка Scrapy Shell в командной строке
Scrapy поставляется со встроенной оболочкой, что помогает отладить код скрапинга в режиме реального времени. С ним можно быстро протестировать XPath-выражения или CSS селекторы. Это очень крутой инструмент для написания веб скраперов, и я всегда им пользуюсь!
Можно настроить Scrapy Shell на использование другой консоли вместо стандартной консоли Python как IPython. У вас появится возможность автозаполнения и другие приятные бонусы вроде цветного вывода.
Для его использования в оболочке Scrapy Shell нужно добавить следующую строку в файл scrapy.cfg:
|
1 |
shell = ipython |
После завершения конфигурации можно использовать оболочку Scrapy:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
$ scrapy shell --nolog [s] Available Scrapy objects: [s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc) [s] crawler <scrapy.crawler.Crawler object at 0x108147eb8> [s] item {} [s] settings <scrapy.settings.Settings object at 0x108d10978> [s] Useful shortcuts: [s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed) [s] fetch(req) Fetch a scrapy.Request and update local objects [s] shelp() Shell help (print this help) [s] view(response) View response in a browser In [1]: |
Можно начать выборку URL следующим простым действием:
|
1 |
fetch('https://clever-lichterman-044f16.netlify.com/products/taba-cream.1/') |
Она начнется с загрузки файла /robot.txt
|
1 |
[scrapy.core.engine] DEBUG: Crawled (404) <GET https://clever-lichterman-044f16.netlify.com/robots.txt> (referer: None) |
В данном случае нет никакого robot.txt, поэтому мы получаем 404 HTTP код. Если бы у нас был файл robot.txt, по умолчанию Scrapy придерживался бы правил.
Можно отключить такое поведение, изменив boolean параметр в settings.py:
|
1 |
ROBOTSTXT_OBEY = True |
После этого у вас должен появится лог подобного рода:
|
1 |
[scrapy.core.engine] DEBUG: Crawled (200) <GET https://clever-lichterman-044f16.netlify.com/products/taba-cream.1/> (referer: None) |
Теперь можно увидеть объект ответа, заголовки ответа и попробовать различные XPath выражения и CSS селекторы, чтобы извлечь нужные данные.
Увидеть ответ прямо в браузере, можно использовав данную функцию:
|
1 |
view(response) |
Обратите внимание, что страница будет плохо отображаться в браузере по многим причинам. Это могут быть проблемы с CORS, не выполненный Javascript код или относительные URL для ресурсов, которые не будут работать локально.
Оболочка Scrapy похожа на обычную оболочку Python, поэтому не бойтесь загружать в нее свои любимые скрипты или функции.
Извлечение данных с сайта через Scrapy
Scrapy по умолчанию не выполняет Javascript код. По этой причине при попытке сделать скрапинг на сайте, что использует Javascript-фреймворки вроде Angular или React.js, у вас могут возникнуть проблемы с получением доступа к запрашиваемым данным.
Попробуем использовать некоторые XPath выражения для извлечения названия и цены продукта:
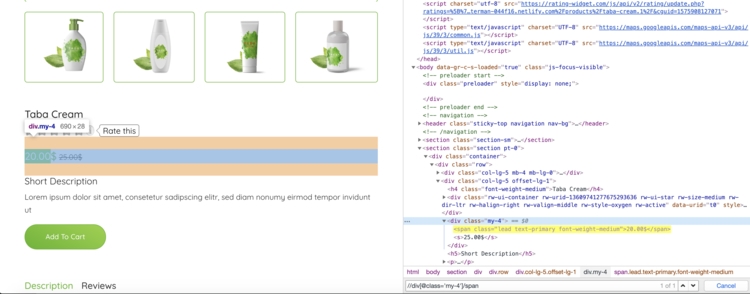
Для извлечения цены мы используем выражение XPath, выберем первый span после div с классом my-4
|
1 2 |
In [16]: response.xpath("//div[@class='my-4']/span/text()").get() Out[16]: '20.00$' |
Я мог также использовать следующий CSS селектор:
|
1 2 |
In [21]: response.css('.my-4 span::text').get() Out[21]: '20.00$' |
Создаем Scrapy Spider
В Scrapy, Spider является классом, где определяется поведение при анализе (какие ссылки или URL должны пройти через скрапинг) и при скрапинге (что нужно извлечь).
Предусмотрено несколько этапов, которые Spider использует для скрапинга вебсайта:
- Все начинается с просмотра атрибута класса
start_urlsи вызова этих URL-адресов с помощью методаstart_requests(). Вы можете переопределить этот метод, если нужно изменить HTTP verb, добавить некоторые параметры в запрос (например, отправив запросPOSTвместоGET). - Затем генерируется объект Request для каждого URL и отправляется ответ в функцию обратного вызова
parse(). - Затем метод
parse()извлекает данные (в нашем случае — цену продукта, изображение, описание, заголовок) и возвращает либо словарь, объект Item, запрос или итерацию.
Может показаться удивительным, что метод parse может возвращать так много разных объектов. Это сделано для гибкости. Допустим, вы хотите сделать скрапинг онлайн магазина, на котором нет карты сайта. Вы можете начать со скрапинга товарных категорий, это будет первый метод парсинга.
Данный метод затем передает объект Request для каждой категории продуктов новому методу обратного вызова parse2(). Для каждой категории нужно обрабатывать нумерацию страниц. Затем для каждого продукта производится фактический скрапинг, что генерирует элемент и третью функцию parse.
С Scrapy можно возвращать данные скрапинга в виде простого словаря Python, но рекомендуется использовать встроенный класс Scrapy Item. Это простой контейнер для данных скрапинга. Scrapy будет просматривать его поля для экспорта данных в различные форматы (JSON / CSV…), источника элемента и многого другого.
Далее показан базовый класс Product:
|
1 2 3 4 5 6 7 |
import scrapy class Product(scrapy.Item): product_url = scrapy.Field() price = scrapy.Field() title = scrapy.Field() img_url = scrapy.Field() |
Теперь можно сгенерировать Spider при помощи командной строки:
|
1 |
scrapy genspider myspider mydomain.com |
Также это можно сделать вручную, поместив код Spider внутри папки /spiders.
В Scrapy есть разные типы Spider, предназначенные для решения самых частых случаев веб-скрапинга:
Spider, который мы будем использовать, принимает списокstart_urlsи скрапит каждый элемент через методparse.CrawlSpiderпереходит по ссылкам, которые соответствуют определенным набором правил.SitemapSpiderизвлекается URL, определенные в карте сайта.- Многие другие.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# -*- coding: utf-8 -*- import scrapy from product_scraper.items import Product class EcomSpider(scrapy.Spider): name = 'ecom_spider' allowed_domains = ['clever-lichterman-044f16.netlify.com'] start_urls = ['https://clever-lichterman-044f16.netlify.com/products/taba-cream.1/'] def parse(self, response): item = Product() item['product_url'] = response.url item['price'] = response.xpath("//div[@class='my-4']/span/text()").get() item['title'] = response.xpath('//section[1]//h2/text()').get() item['img_url'] = response.xpath("//div[@class='product-slider']//img/@src").get(0) return item |
В данном классе EcomSpider есть два запрашиваемых атрибута:
name, что является названиемSpider(можно запустить при использованииscrapy runspider spider_name)start_urls, что является начальным URL
Атрибут allow_domains необязателен, но важен, когда вы используете CrawlSpider, который может переходить по ссылкам в разных доменах.
Затем поля Product просто заполняются при помощи выражений XPath для извлечения нужных данных, и возвращается элемент.
Чтобы экспортировать результат в JSON (его также можете экспортировать в CSV), можно запустить код следующим образом:
|
1 |
scrapy runspider ecom_spider.py -o product.json |
После этого вы должны получить требуемый файл JSON:
|
1 2 3 4 5 6 7 8 |
[ { "product_url": "https://clever-lichterman-044f16.netlify.com/products/taba-cream.1/", "price": "20.00$", "title": "Taba Cream", "img_url": "https://clever-lichterman-044f16.netlify.com/images/products/product-2.png" } ] |
Во время извлечения данных с веб страницы вы можете столкнуться со следующими проблемами:
- На одном и том же сайте лейаут страницы и основной HTML могут отличаться. При скрапинге онлайн магазина вам часто будет встречаться стандартная цена и цена после скидки, у которых разные XPath и CSS селекторы.
- Данные могут быть представлены несколько беспорядочно, поэтому зачастую требуется последующая обработка. Опять же, в онлайн магазине могут возникнуть проблемы с различным отображением цен, например — ($1.00, $1, $1,00).
Scrapy поставляется со встроенным решением проблемы — ItemLoaders. Это интересный способ заполнения объекта Product.
Вы можете добавить несколько выражений XPath одному и тому же полю, и он проверит все последовательно. По умолчанию, если найдено несколько XPath, они будут помещены в список.
В официальной документации Scrapy можно найти много примеров операций ввода и вывода данных.
Это очень полезно, если вам понадобится изменить или очистить извлеченные данные. К примеру, получение списка доступных валют, изменение одной единицы измерения в другую (сантиметры в метры, градусы Цельсия в Фаренгейты и так далее).
На нашей веб странице можно найти название продукта через разные XPath выражения: //title и //section[1]//h2/text()
В данном случае можно использовать Itemloader:
|
1 2 3 4 5 6 7 |
def parse(self, response): l = ItemLoader(item=Product(), response=response) l.add_xpath('price', "//div[@class='my-4']/span/text()") l.add_xpath('title', '//section[1]//h2/text()') l.add_xpath('title', '//title') l.add_value('product_url', response.url) return l.load_item() |
Обычно требуется только первый совпадающий XPath, поэтому нужно добавить output_processor=TakeFirst() в конструктор поля элемента.
В нашем случае нужен только первый соответствующий XPath для каждого поля, поэтому лучшим подходом будет создать собственный ItemLoader и по умолчанию output_processor для первого подходящего XPath:
|
1 2 3 4 5 6 7 8 9 |
from scrapy.loader import ItemLoader from scrapy.loader.processors import TakeFirst, MapCompose, Join def remove_dollar_sign(value): return value.replace('$', '') class ProductLoader(ItemLoader): default_output_processor = TakeFirst() price_in = MapCompose(remove_dollar_sign) |
Мы также добавили price_in, что является вводным процессором для удаления знака доллара из цены. Здесь используется MapCompose, что является встроенным процессором, который принимает несколько функций, которые выполняются последовательно. Можно добавить столько функций, сколько хочется. Нужно добавить _in или _out в название поля Item для добавления к нему процессора ввода или вывода.
Существует довольно много процессоров, прочитать о них подробнее можно в официальной документации.
Скрапинг нескольких страниц через Scrapy
Теперь, когда мы познакомились со скрапингом одной страницы, пришло время научиться скрапить несколько страниц. Например весь каталог товаров. Как мы видели ранее, есть разные виды Spider.
Когда нужно сделать скрапинг всего каталога товаров, первым делом нужно обратить внимание на карту сайта. Карта сайта создана специально для этого. Она показывает, как устроен сайт.
Зачастую можно найти один в base_url/sitemap.xml. Парсинг карты сайта может быть сложным, однако Scrapy может значительно облегчить процесс.
В нашем случае карту сайта можно найти здесь: https://clever-lichterman-044f16.netlify.com/sitemap.xml
Если просмотреть карту сайта, можно увидеть много URL, которые нам не особо интересны, например, домашняя страница, записи блоги и некоторые другие:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
<url> <loc> https://clever-lichterman-044f16.netlify.com/blog/post-1/ </loc> <lastmod>2019-10-17T11:22:16+06:00</lastmod> </url> <url> <loc> https://clever-lichterman-044f16.netlify.com/products/ </loc> <lastmod>2019-10-17T11:22:16+06:00</lastmod> </url> <url> <loc> https://clever-lichterman-044f16.netlify.com/products/taba-cream.1/ </loc> <lastmod>2019-10-17T11:22:16+06:00</lastmod> </url> |
К счастью, можно отфильтровать адреса URL и парсить только те, что соответствуют определенному паттерну. Это не сложно, мы будем использовать только те URL, внутри адресов которых значится совпадение с /products/.
|
1 2 3 4 5 6 7 8 9 |
class SitemapSpider(SitemapSpider): name = "sitemap_spider" sitemap_urls = ['https://clever-lichterman-044f16.netlify.com/sitemap.xml'] sitemap_rules = [ ('/products/', 'parse_product') ] def parse_product(self, response): # ... скрапинг товара ... |
Запустить скрипт для скрапинга всех товаров и экспорта результата в CSV файл можно следующим образом: scrapy runspider sitemap_spider.py -o output.csv
Что же делать, если на сайте нет никакой карты? У Scrapy есть решение и для таких случаев.
Позвольте представить вам… CrawlSpider.
CrawlSpider изучит сайт, начав со списка start_urls. Затем для каждого url он извлечет все ссылки, базирующиеся на списке Rule. В нашем случае все довольно просто, у товаров одинаковый URL паттерн /products/product_title, поэтому потребуется отфильтровать только эти URL.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
import scrapy from scrapy.spiders import CrawlSpider, Rule from scrapy.linkextractors import LinkExtractor from product_scraper.productloader import ProductLoader from product_scraper.items import Product class MySpider(CrawlSpider): name = 'crawl_spider' allowed_domains = ['clever-lichterman-044f16.netlify.com'] start_urls = ['https://clever-lichterman-044f16.netlify.com/products/'] rules = ( Rule(LinkExtractor(allow=('products', )), callback='parse_product'), ) def parse_product(self, response): # .. парсинг товара |
Как видите, все встроенные «Пауки» довольно легко использовать. Начинать процесс с нуля было бы намного проблематичнее.
Вместе со Scrapy вам не нужно думать о логике парсинга, добавлении новых URL в очередь, фиксировании уже изученных адресов и многопоточности.
Заключение
В этом руководстве мы рассмотрели основы скрапинга веб страницы через Scrapy и то, как с ним можно решить самые распространенные проблемы. Конечно, была описана лишь малая часть функционала Scrapy.
Если до этого вы по большей части занимались скрапингом «вручную», используя такие инструменты, как BeautifulSoup / Requests, будет несложно оценить помощь Scrapy. Он значительно экономит время и создает удобные скраперы данных.
Надеюсь, вам понравился этот урок по Scrapy, и вам захочется поэкспериментировать с новым инструментом.
Для более подробного ознакомления со Scrapy можете изучить официальную документацию.
Удачного скрапинга!

Являюсь администратором нескольких порталов по обучению языков программирования Python, Golang и Kotlin. В составе небольшой команды единомышленников, мы занимаемся популяризацией языков программирования на русскоязычную аудиторию. Большая часть статей была адаптирована нами на русский язык и распространяется бесплатно.
E-mail: vasile.buldumac@ati.utm.md
Образование
Universitatea Tehnică a Moldovei (utm.md)
- 2014 — 2018 Технический Университет Молдовы, ИТ-Инженер. Тема дипломной работы «Автоматизация покупки и продажи криптовалюты используя технический анализ»
- 2018 — 2020 Технический Университет Молдовы, Магистр, Магистерская диссертация «Идентификация человека в киберпространстве по фотографии лица»