
В данном руководстве, мы построим Рекуррентную Нейронную Сеть (Recurrent Neural Network, далее — RNN) в PyTorch, которая будет классифицировать имена людей по их языкам. Предположим, что у читателя есть основы понимания PyTorch и машинного обучения в Python.
В конце данного руководства, мы сможем предугадывать язык на котором разговаривает человек по его имени.
Набор данных имён, приведенный в данном руководстве можно скачать здесь: data.zip
Это руководство — адаптация официальной документации PyTorch. Вы можете узнать больше из документации.
Другие статьи по PyTorch
Краткое содержание
- Предварительная обработка данных
- Превращение имен в тензоры PyTorch
- Создание RNN
- Тестирование RNN
- Тренировка RNN
- Построение графиков
- Оценка результатов
- Угадывание новых имен
- Вывод
Установка PyTorch
Заходим на сайт: https://pytorch.org/
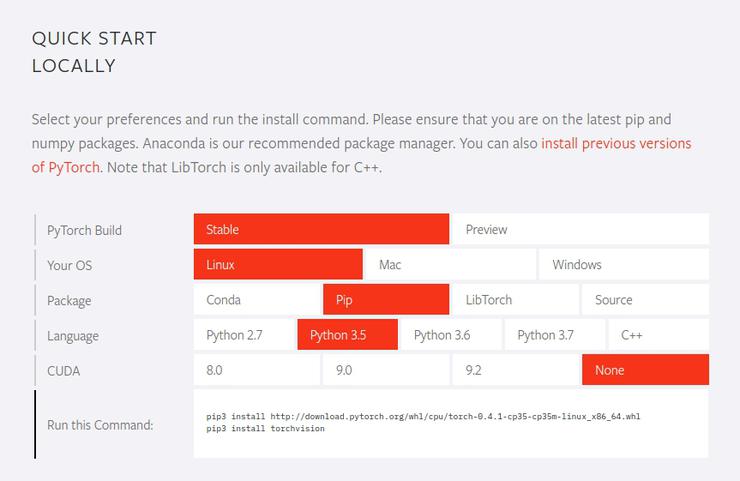
На сайте будет вот такая форма, где вы сможете выбрать свою операционную систему, менеджер пакетов, версия Python (Есть даже для самого нового Python 3.7) и версия CUDA (можно выбрать None если он не установлен). В зависимости от вашего выбора, вы получите инструкцию по установке.
Предварительная обработка данных
Как и в случае с любой другой задачей для машинного обучения, мы начнем с загрузки и подготовки нашего набора данных. После загрузки набора данных, обратите внимание на то, что в папке с данными есть папка под названием names. Она содержит текстовые файлы с фамилиями на восемнадцати разных именах.
Чтобы загрузить все файлы одним махом, мы используем модуль Python под названием glob. Модуль glob находит все совпадения названий путей по особому шаблону, в соответствии с правилами, используемыми в оболочке Unix. Результаты возвращаются в произвольном порядке. Мы используем его для загрузки всех файлов с окончанием .txt в папку.
|
1 2 3 4 |
import glob all_text_files = glob.glob('data/names/*.txt') print(all_text_files) |

В данный момент, названия находятся в формате Unicode. Однако, нам нужно конвертировать их в стандарт ASCII. Это поможет с удалением диакритиков в словах. Например, французское имя Béringer будет конвертировано в Beringer.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import unicodedata import string all_letters = string.ascii_letters + " .,;'" n_letters = len(all_letters) def unicode_to_ascii(s): return ''.join( c for c in unicodedata.normalize('NFD', s) if unicodedata.category(c) != 'Mn' and c in all_letters ) print(unicode_to_ascii('Béringer')) |
Следующий шаг — создание словаря со списком имен для каждого языка.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
category_languages = {} all_categories = [] def readLines(filename): lines = open(filename).read().strip().split('\n') return [unicode_to_ascii(line) for line in lines] for filename in all_text_files: category = filename.split('/')[-1].split('.')[0] all_categories.append(category) languages = readLines(filename) category_languages[category] = languages no_of_languages = len(all_categories) print('There are {} langauages'.format(no_of_languages)) |
Мы можем ознакомиться с первыми 15 именами во французском словаре, как показано ниже.

Превращение имен в тензоры PyTorch
Работая с данными в PyTorch, нам нужно конвертировать их в тензоры PyTorch. Это очень похоже на массивы NumPy. В нашем случае, нам нужно конвертировать каждую букву в тензор torch. Это будет один вектор, наполненный нулями, за исключением единицы в индексе текущей буквы. Посмотрим, как это работает, и затем конвертируем M в один вектор.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
import torch import string all_letters = string.ascii_letters + " .,;'" n_letters = len(all_letters) def letter_to_tensor(letter): tensor = torch.zeros(1, n_letters) letter_index = all_letters.find(letter) tensor[0][letter_index] = 1 return tensor def line_to_tensor(line): tensor = torch.zeros(len(line), 1, n_letters) for li, letter in enumerate(line): letter_index = all_letters.find(letter) tensor[li][0][letter_index] = 1 return tensor |
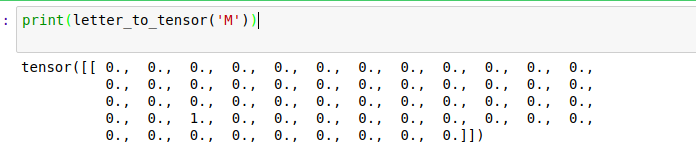
Чтобы сформировать одно имя, нам нужно соединить несколько векторов, чтобы создать двухмерную матрицу в numpy.
Создание RNN
При создании нейронной сети в PyTorch, мы используем torch.nn.Module, который является основным классом для всех модулей нейронных сетей. В то же время, torch.autograd предоставляет классы и функции, реализующие автоматическое дифференцирование произвольных скалярных функций. И torch.nn.LogSoftmax применяет функцию Log(Softmax(x)) к n-мерному тензору ввода.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 |
import torch import torch.nn as nn from torch.autograd import Variable import unicodedata import string import glob all_letters = string.ascii_letters + " .,;'" n_letters = len(all_letters) def unicode_to_ascii(s): return ''.join( c for c in unicodedata.normalize('NFD', s) if unicodedata.category(c) != 'Mn' and c in all_letters ) def letter_to_tensor(letter): tensor = torch.zeros(1, n_letters) letter_index = all_letters.find(letter) tensor[0][letter_index] = 1 return tensor def line_to_tensor(line): tensor = torch.zeros(len(line), 1, n_letters) for li, letter in enumerate(line): letter_index = all_letters.find(letter) tensor[li][0][letter_index] = 1 return tensor class RNN(nn.Module): def __init__(self, input_size, hidden_size, output_size): super(RNN, self).__init__() self.input_size = input_size self.hidden_size = hidden_size self.output_size = output_size self.i2h = nn.Linear(input_size + hidden_size, hidden_size) self.i2o = nn.Linear(input_size + hidden_size, output_size) self.softmax = nn.LogSoftmax() def forward(self, input, hidden): combined = torch.cat((input, hidden), 1) hidden = self.i2h(combined) output = self.i2o(combined) output = self.dim = output return output, hidden def init_hidden(self): return Variable(torch.zeros(1, self.hidden_size)) if __name__ == '__main__': category_languages = {} all_categories = [] all_text_files = glob.glob('data/names/*.txt') for filename in all_text_files: category = filename.split('/')[-1].split('.')[0] all_categories.append(category) languages = [unicode_to_ascii(line.strip()) for line in open(filename).readlines()] category_languages[category] = languages no_of_languages = len(all_categories) |
Тестирование RNN
Мы начнем с создания экземпляра класса RNN и передачи необходимых аргументов.
|
1 2 |
n_hidden = 128 rnn = RNN(n_letters, n_hidden, no_of_languages) |
Мы хотим, чтобы сеть давала нам вероятность каждого языка. Чтобы достичь этого, мы передадим тензор текущей буквы.
|
1 2 3 4 5 6 7 8 9 10 11 |
input = Variable(letter_to_tensor('D')) hidden = rnn.init_hidden() output, next_hidden = rnn(input, hidden) print('output.size =', output.size()) input = Variable(line_to_tensor('Derrick')) hidden = Variable(torch.zeros(1, n_hidden)) output, next_hidden = rnn(input[0], hidden) print(output) |
Наш __main__ будет выглядеть так:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
if __name__ == '__main__': category_languages = {} all_categories = [] all_text_files = glob.glob('data/names/*.txt') for filename in all_text_files: category = filename.split('/')[-1].split('.')[0] all_categories.append(category) languages = [unicode_to_ascii(line.strip()) for line in open(filename).readlines()] category_languages[category] = languages no_of_languages = len(all_categories) n_hidden = 128 rnn = RNN(n_letters, n_hidden, no_of_languages) input = Variable(letter_to_tensor('D')) hidden = rnn.init_hidden() output, next_hidden = rnn(input, hidden) print('output.size =', output.size()) input = Variable(line_to_tensor('Derrick')) hidden = Variable(torch.zeros(1, n_hidden)) output, next_hidden = rnn(input[0], hidden) print(output) |
Результат работы:
|
1 2 3 4 |
output.size = torch.Size([1, 18]) tensor([[-0.0286, 0.0233, -0.1256, 0.0964, -0.0281, -0.0697, -0.0022, 0.0985, -0.0928, -0.1271, -0.0176, 0.0327, -0.0561, -0.0078, -0.0051, 0.0560, -0.0135, -0.0472]], grad_fn=<ThAddmmBackward>) |
Тренировка RNN
Чтобы получить вероятность для каждого языка, мы используем Tensor.topk для получения индекса наибольшего значения.
|
1 2 3 4 5 6 |
def category_from_output(output): top_n, top_i = output.data.topk(1) category_i = top_i[0][0] return all_categories[category_i], category_i print(category_from_output(output)) |
Далее, нам нужен быстрый способ получить имя и его выдачу (output). На данный момент у нас такой файл main.py (мы выделили участки кода которые были добавлены):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 |
import torch import torch.nn as nn from torch.autograd import Variable import unicodedata import string import glob import random all_letters = string.ascii_letters + " .,;'" n_letters = len(all_letters) def unicode_to_ascii(s): return ''.join( c for c in unicodedata.normalize('NFD', s) if unicodedata.category(c) != 'Mn' and c in all_letters ) def letter_to_tensor(letter): tensor = torch.zeros(1, n_letters) letter_index = all_letters.find(letter) tensor[0][letter_index] = 1 return tensor def line_to_tensor(line): tensor = torch.zeros(len(line), 1, n_letters) for li, letter in enumerate(line): letter_index = all_letters.find(letter) tensor[li][0][letter_index] = 1 return tensor def category_from_output(output): top_n, top_i = output.data.topk(1) category_i = top_i[0][0] return all_categories[category_i], category_i def random_training_pair(): category = random.choice(all_categories) line = random.choice(category_languages[category]) category_tensor = Variable(torch.LongTensor([all_categories.index(category)])) line_tensor = Variable(line_to_tensor(line)) return category, line, category_tensor, line_tensor class RNN(nn.Module): def __init__(self, input_size, hidden_size, output_size): super(RNN, self).__init__() self.input_size = input_size self.hidden_size = hidden_size self.output_size = output_size self.i2h = nn.Linear(input_size + hidden_size, hidden_size) self.i2o = nn.Linear(input_size + hidden_size, output_size) self.softmax = nn.LogSoftmax() def forward(self, input, hidden): combined = torch.cat((input, hidden), 1) hidden = self.i2h(combined) output = self.i2o(combined) output = self.dim = output return output, hidden def init_hidden(self): return Variable(torch.zeros(1, self.hidden_size)) if __name__ == '__main__': category_languages = {} all_categories = [] all_text_files = glob.glob('data/names/*.txt') for filename in all_text_files: category = filename.split('/')[-1].split('.')[0] all_categories.append(category) languages = [unicode_to_ascii(line.strip()) for line in open(filename).readlines()] category_languages[category] = languages no_of_languages = len(all_categories) n_hidden = 128 rnn = RNN(n_letters, n_hidden, no_of_languages) # Тренировка RNN for i in range(10): category, line, category_tensor, line_tensor = random_training_pair() print('category =', category, '/ line =', line) |
Результат выполнения:
|
1 2 3 4 5 6 7 8 9 10 |
category = Irish / line = John category = German / line = Raske category = German / line = Becke category = Korean / line = Mo category = Spanish / line = Rojo category = Arabic / line = Kanaan category = German / line = Kundert category = Irish / line = Mcguire category = Chinese / line = Duan category = Chinese / line = Chu |
Следующий шаг – определение функции loss и создание оптимизатора, который будет обновлять параметры модели, в соответствии с её градиентами. Мы также устанавливаем скорость обучения нашей модели.
|
1 2 3 4 |
criterion = nn.NLLLoss() learning_rate = 0.005 optimizer = torch.optim.SGD(rnn.parameters(), lr=learning_rate) |
Мы двигаемся дальше, и определяем функцию, которая будет создавать тензоры ввода и вывода, сравним итоговую выдачу с целевой, и наконец, выполним обратное распространение (back-propagation).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
def train(category_tensor, line_tensor): rnn.zero_grad() hidden = rnn.init_hidden() for i in range(line_tensor.size()[0]): output, hidden = rnn(line_tensor[i], hidden) loss = criterion(output, category_tensor) loss.backward() optimizer.step() return output, loss.data[0] |
Следующий шаг – это запуск нескольких примеров, используя тренировочную функцию, поскольку мы отслеживаем потери для последующего построения графика. В данном примере было использовано библиотека math и функция floor().
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
import time import math n_epochs = 100000 print_every = 5000 plot_every = 1000 current_loss = 0 all_losses = [] def time_since(since): now = time.time() s = now - since m = math.floor(s / 60) s -= m * 60 return '%dm %ds' % (m, s) start = time.time() for epoch in range(1, n_epochs + 1): category, line, category_tensor, line_tensor = random_training_pair() output, loss = train(category_tensor, line_tensor) current_loss += loss if epoch % print_every == 0: guess, guess_i = category_from_output(output) correct = '✓' if guess == category else '✗ (%s)' % category print('%d %d%% (%s) %.4f %s / %s %s' % (epoch, epoch / n_epochs * 100, time_since(start), loss, line, guess, correct)) if epoch % plot_every == 0: all_losses.append(current_loss / plot_every) current_loss = 0 |
Построение графиков
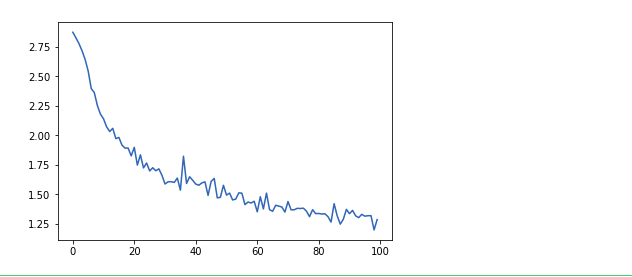
Мы создаем графики на основе результатов при помощи pyplot от Matplotlib. График покажет нам скорость обучения нашей нейронной сети.
|
1 2 3 4 5 6 7 |
import matplotlib.pyplot as plt import matplotlib.ticker as ticker %matplotlib inline plt.figure() plt.plot(all_losses) |
Оценка результатов
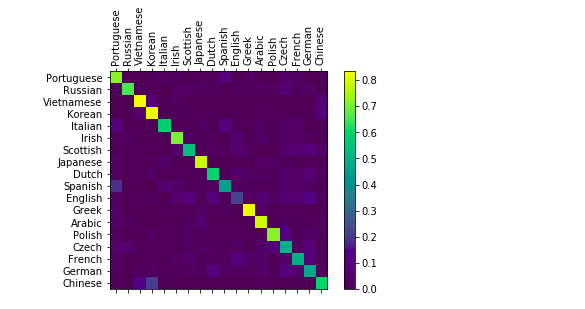
Мы создадим запутанную матрицу в numpy, чтобы увидеть, как нейронная сеть проявляет себя в разных категориях. Яркие точки на основной оси показывают языки, которые были выбраны неправильно.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
confusion = torch.zeros(no_of_languages, no_of_languages) n_confusion = 10000 def evaluate(line_tensor): hidden = rnn.init_hidden() for i in range(line_tensor.size()[0]): output, hidden = rnn(line_tensor[i], hidden) return output for i in range(n_confusion): category, line, category_tensor, line_tensor = random_training_pair() output = evaluate(line_tensor) guess, guess_i = category_from_output(output) category_i = all_categories.index(category) confusion[category_i][guess_i] += 1 for i in range(no_of_languages): confusion[i] = confusion[i] / confusion[i].sum() fig = plt.figure() ax = fig.add_subplot(111) cax = ax.matshow(confusion.numpy()) fig.colorbar(cax) ax.set_xticklabels([''] + all_categories, rotation=90) ax.set_yticklabels([''] + all_categories) ax.xaxis.set_major_locator(ticker.MultipleLocator(1)) ax.yaxis.set_major_locator(ticker.MultipleLocator(1)) plt.show() |
Угадывание новых имен
Мы определим функцию, которая возьмет имя человека, и вернет языки, которые, скорее всего, родные для этого человека.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
def predict(input_line, n_predictions=3): print('\n> %s' % input_line) output = evaluate(Variable(line_to_tensor(input_line))) topv, topi = output.data.topk(n_predictions, 1, True) predictions = [] for i in range(n_predictions): value = topv[0][i] category_index = topi[0][i] print('(%.2f) %s' % (value, all_categories[category_index])) predictions.append([value, all_categories[category_index]]) predict('Austin') |

Вывод
Если вы хотите узнать побольше о PyTorch, есть масса руководств в официальной документации. Если вы хотите узнать больше о RNN, Брайан Мванги написал фантастический гайд на эту тему.

Являюсь администратором нескольких порталов по обучению языков программирования Python, Golang и Kotlin. В составе небольшой команды единомышленников, мы занимаемся популяризацией языков программирования на русскоязычную аудиторию. Большая часть статей была адаптирована нами на русский язык и распространяется бесплатно.
E-mail: vasile.buldumac@ati.utm.md
Образование
Universitatea Tehnică a Moldovei (utm.md)
- 2014 — 2018 Технический Университет Молдовы, ИТ-Инженер. Тема дипломной работы «Автоматизация покупки и продажи криптовалюты используя технический анализ»
- 2018 — 2020 Технический Университет Молдовы, Магистр, Магистерская диссертация «Идентификация человека в киберпространстве по фотографии лица»